1、Midjourney简介
Midjourney是一个由同名研究实验室开发的人工智能程序,可以根据文本生成图像,生成图片的质量很高,可用于壁纸、插画、漫画、平面设计,logo、APP图标等的灵感创作。适合于设计师、插画师、美术指导、创意总监、自媒体人、创意行业、视觉行业等一切内容创作者。
Midjourney没有自己的客户端,不需要下载与安装。Midjourney现在依托Discord来完成图片生成功能,而Discord其实是一个聊天软件,类似于微信,至于Midjourney则可以理解为微信小程序。因此,我们可以把Midjourney看成是Discord上的一个小程序。
使用Midjourney来生成图片只需要在Discord输入提示词(prompt)即可。Midjourney出图质量和速度与个人电脑性能无关,图片生成整个过程是运行在云端电脑上。
2、MidJourney注册
Midjourney注册大致流程为,先在Discord网站(https://discord.com/)注册一个账号,然后将Midjourney进行授权,之后打开Discord网站输入提示词(prompt)就可以制作图片了。
首先打开打开Discord的注册链接 https://discord.com/register 填写邮箱、用户名、密码等信息,需要注意的是填写出生年月的时候不要填太小,未成年不让使用,最好填20岁以上。点击“继续”后进行验证。
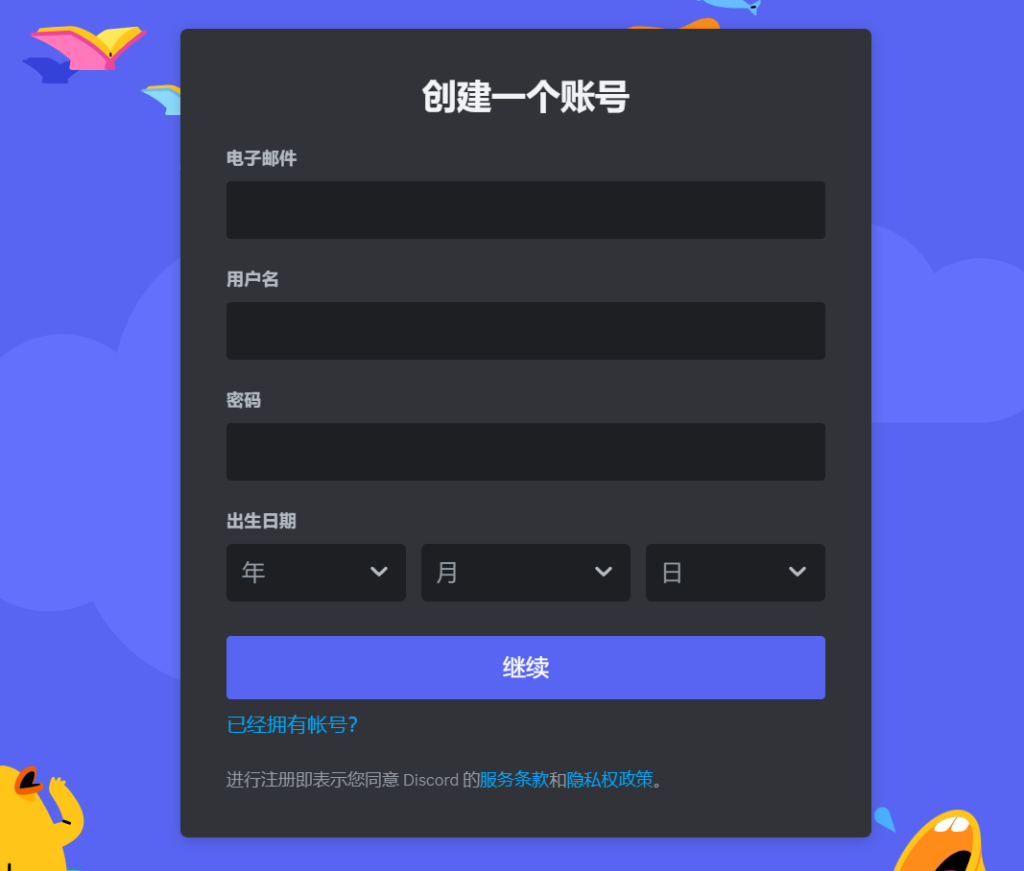
接下来需要真人验证,验证手机号,验证邮箱等多个步骤,中间可能存在多步真人验证,时间略长,需要大家耐心点。
之后进入Discord,点击左边的的+号,创建个人服务器,在弹出的对话框中选择“亲自创建”,选择“仅供我和我的朋友使用”,上传头像(可选)、填写名称就可以了。
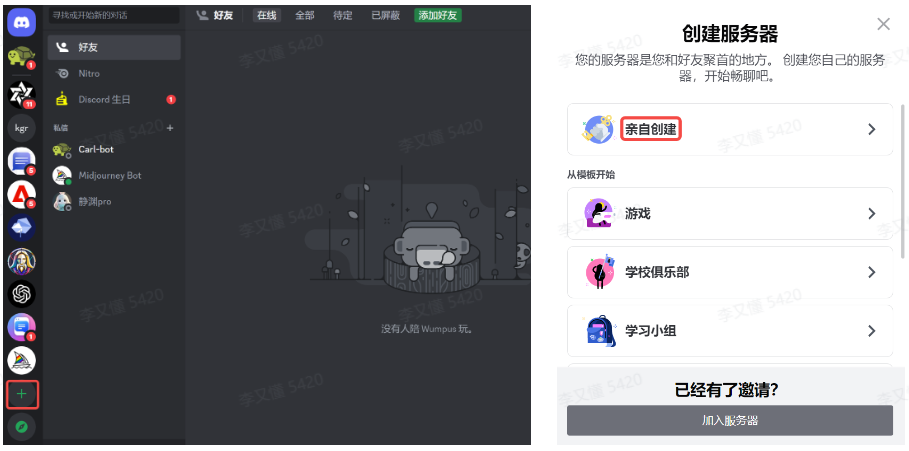
点击左边工具栏上的“探索公开服务器”按钮,然后搜索Midjourney,点击进入。
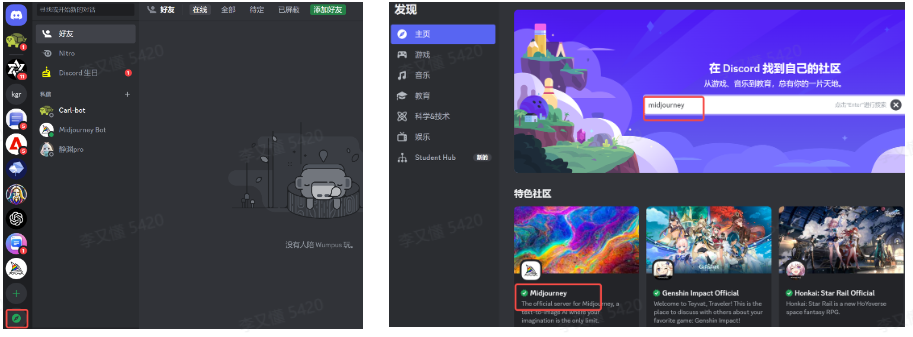
进入一个房间,在左边的聊天室列表中进入一个聊天室,然后在聊天记录中找到一个Midjourney Bot,然后点击,在弹出框中点击”添加至服务器“按钮。在服务器选择框中,选择你刚才新建的服务器,最后点击”授权“按钮即可
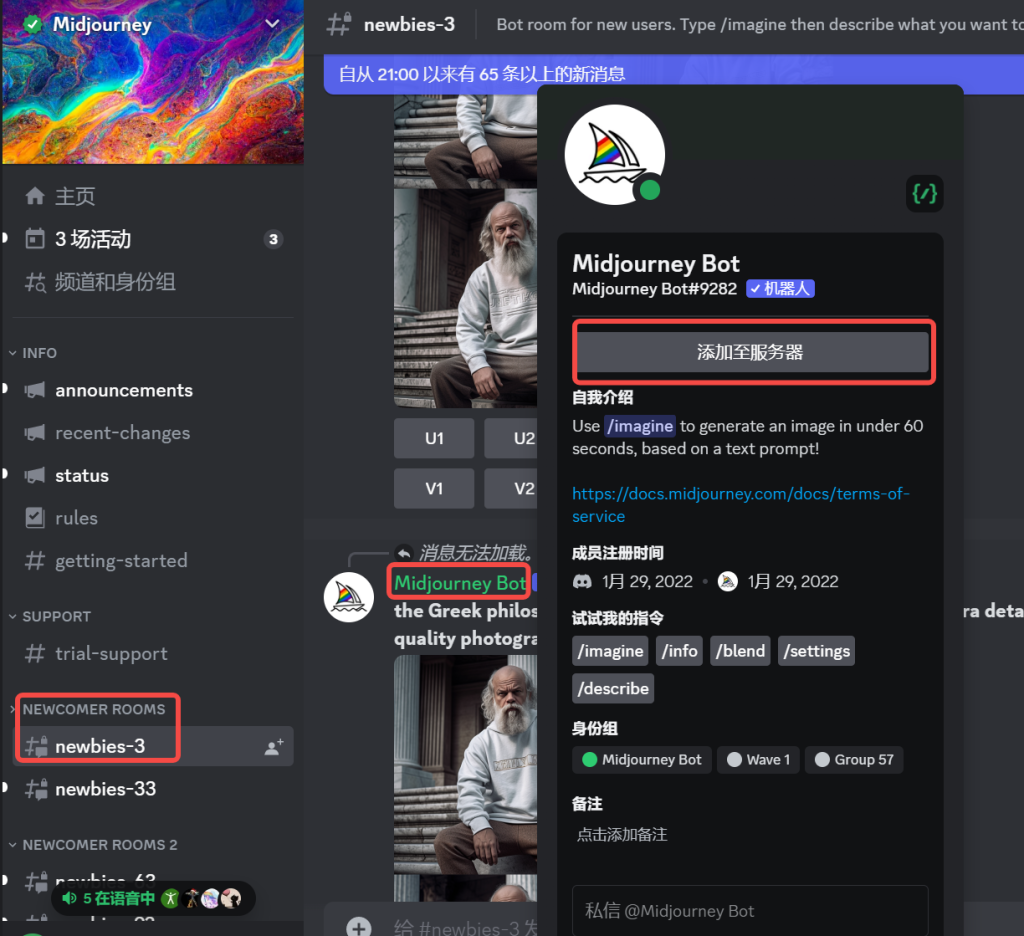
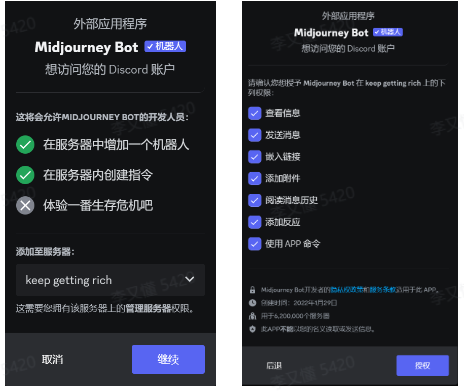
回到自己的服务器,这时候Midjourney机器人已经在聊天室里了,因为现在Midjourney没有免费体验额度了,所以在正式输入提示词(prompt)来生成图片之前,让需要订阅付费使用。在底部的聊天窗口输入”/subscribe“回车,点击”Open subscription page”可以转到订阅页面

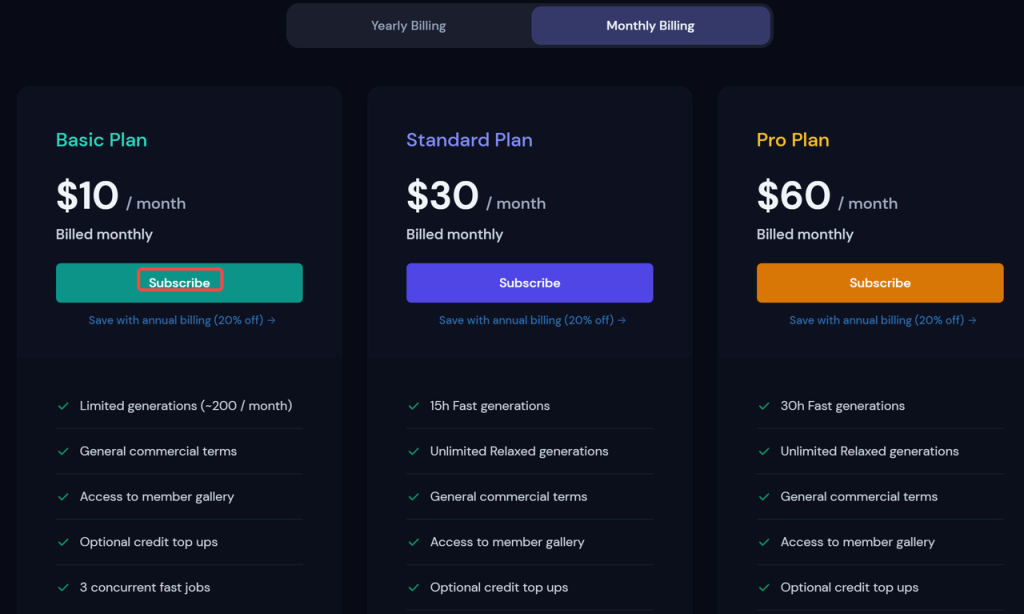
进入到订阅页面之后,会发现套餐有三档:基本、标准和高级,每一档可以包年也可以包月。如果大家平时不是经常使用而是体验的话,可以如下图所示一样选择基本的包月套餐体验一下。然后就是填信用卡信息,国内的信用卡也可以用,但借记卡不行,按照提示付款就行
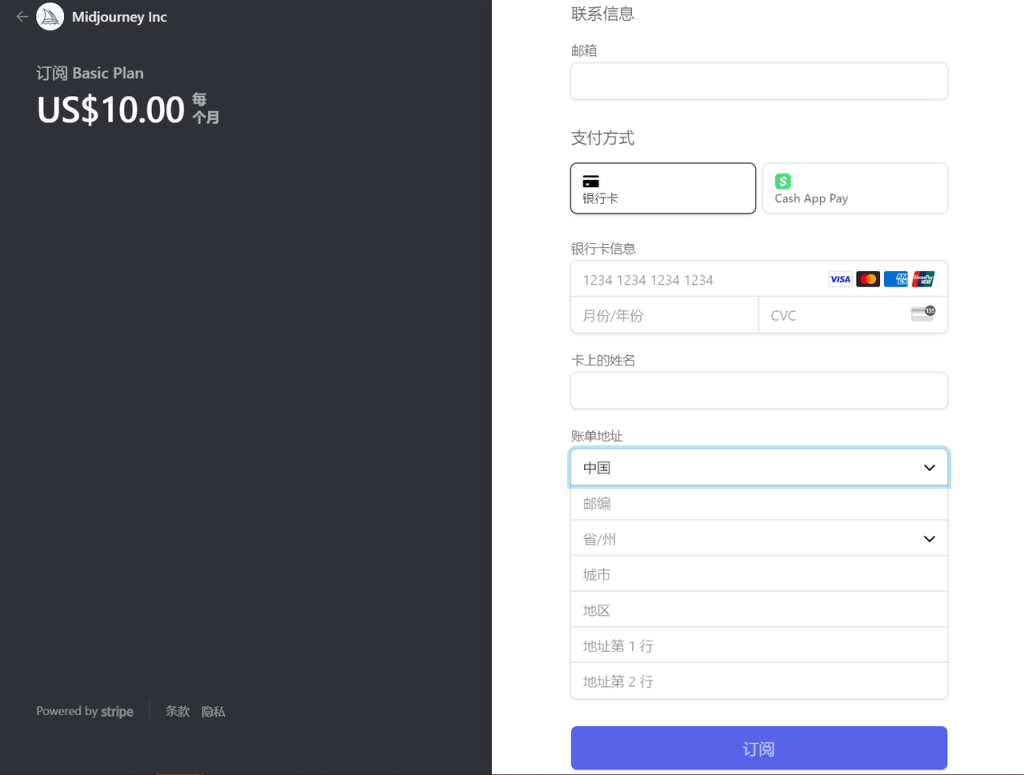
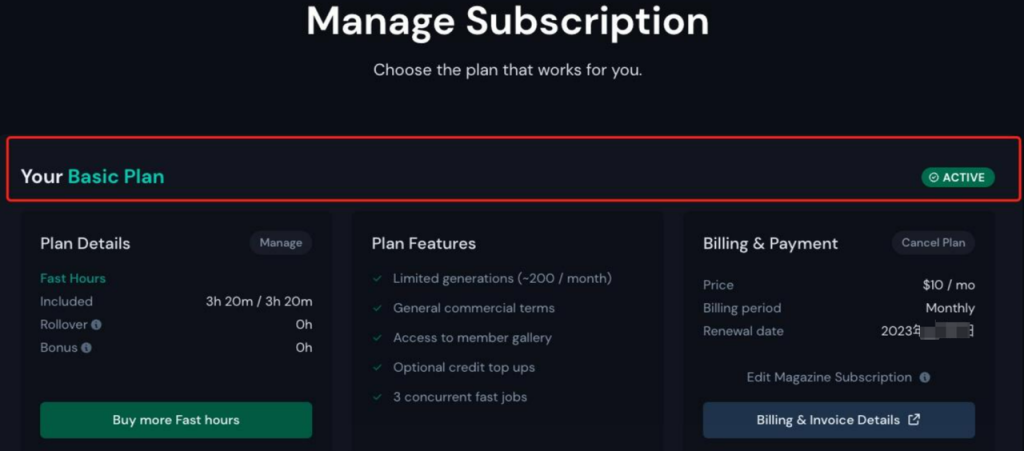
当看到如下界面的时候,意味着付款成功。之后就可以通过输入提示词(prompt)来生成图片了
3、Midjourney 共享账号如何在个人主账号中保留绘图信息
Midjourney 基础套餐中包含的功能是不完整的,很多朋友既想体验完整的Midjourney的功能,又因为平时使用AI绘画的次数比较少,不想花太多的费用。这时候几个人一起拼一个30美金的标准套餐,还是比较划算的。既能享受 Midjourney 的所有功能,每个人付的费用也不多。
但 Midjourney 共享账号有个不足之处,就是很多共享账号都是月抛(一个月之后就不再拼了)。共享账号中的个人绘画记录,在使用期结束之后很有可能因为账号不能再登陆而无法找回。
这时候可以考虑自己再注册一个完全属于个人的Midjourney账号。这个账号不需要购买付费套餐,只用来记录自己共享账号的操作记录。
具体流程是这样的:
- 首先注册主账号,创建频道,并在频道那里点击邀请,生成邀请链接
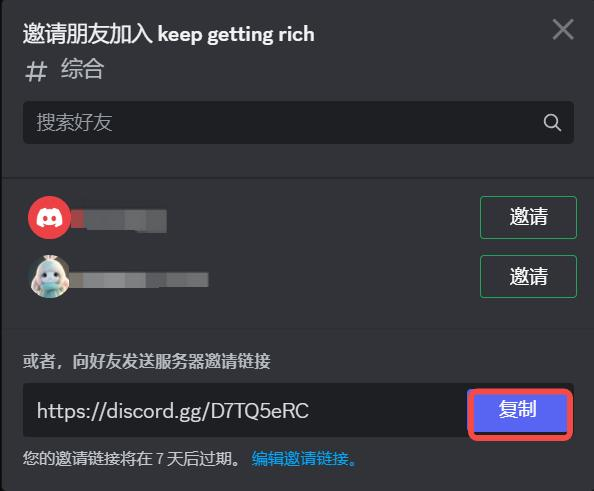
- 再到共享账号中某个频道中输入邀请链接,点加入
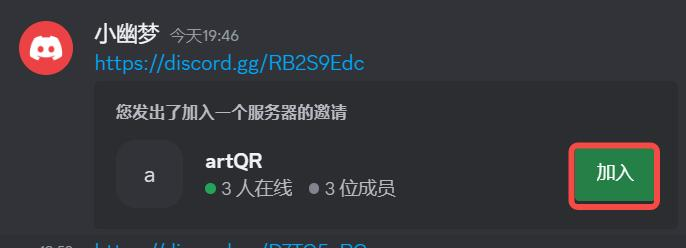
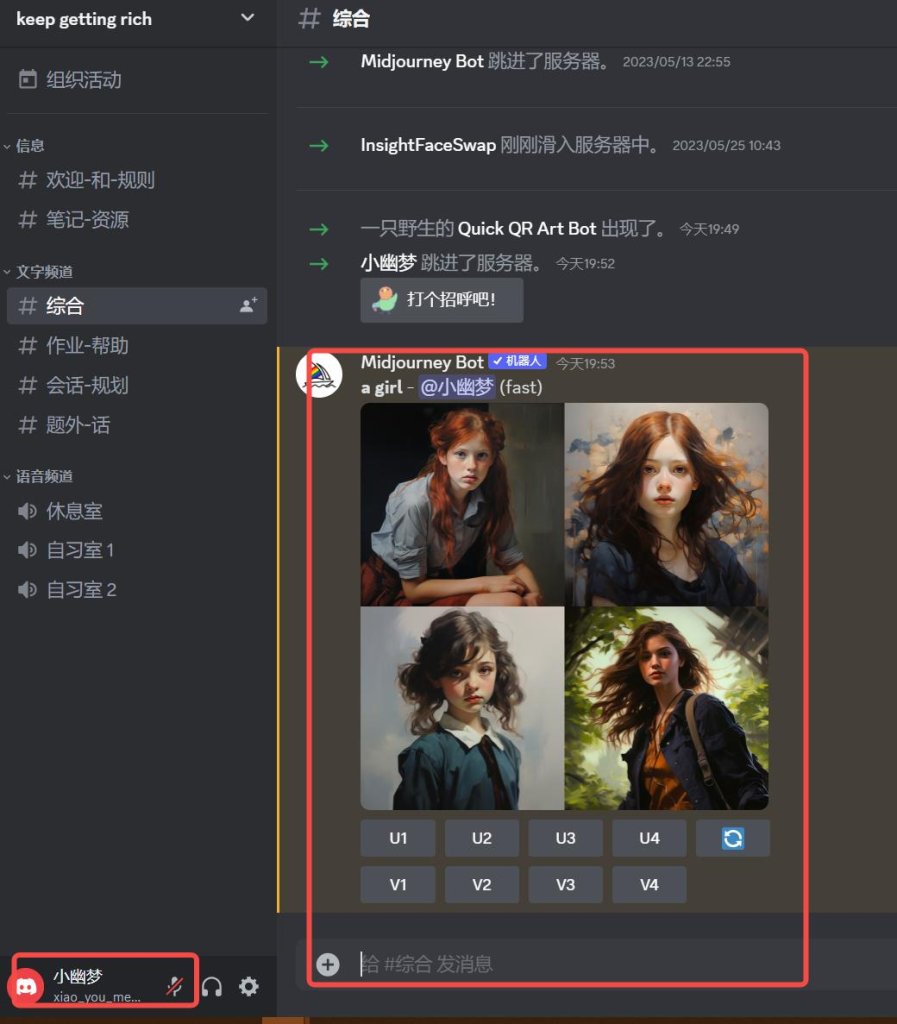
- 然后再在共享账号中作图,你就会发现,在自己的主账号里面也会有同样的操作。这样就算共享号没了也无所谓,自己的主号永远在自己手中,聊天记录也永远存在
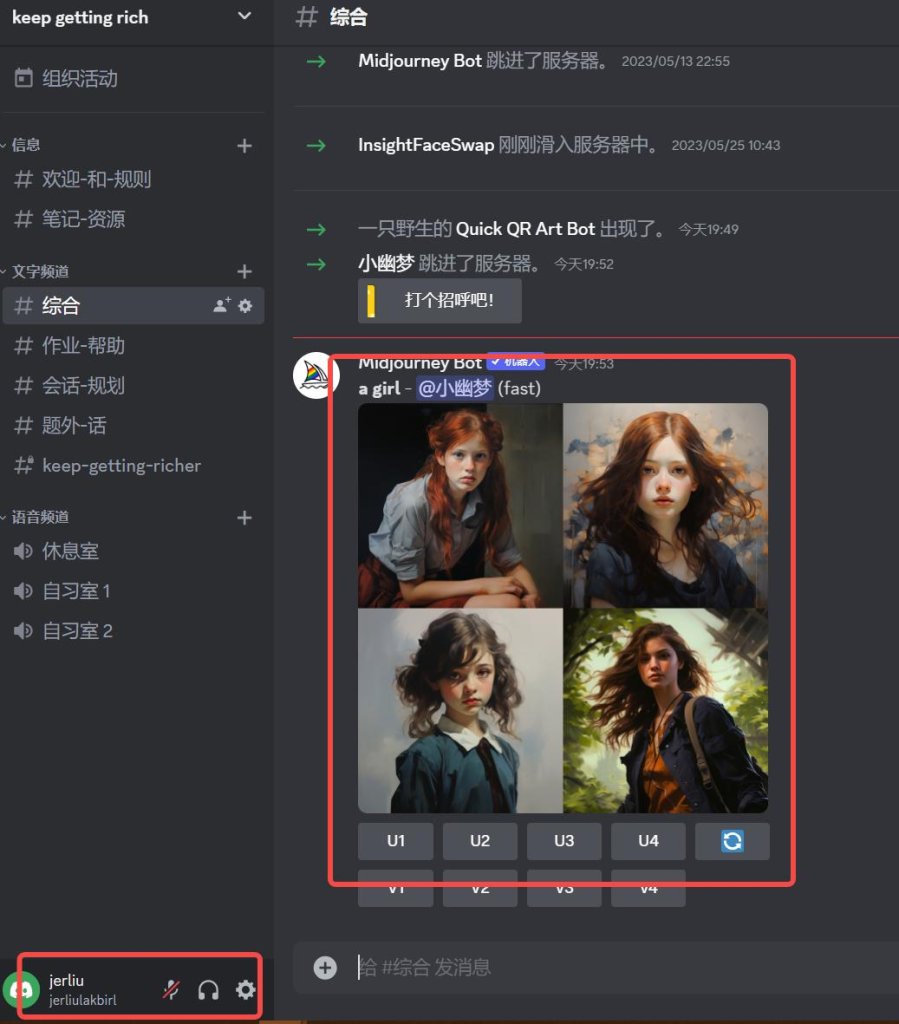
4、MidJourney指令合集
| 指令 | 释义 |
| /imagine | 通过提示词生成图片或者通过垫图和提示词生成图片 |
| /settings | 查看当前Midjourney机器人默认设置 |
| /ask | 获取问题答案 |
| /relax | 切换到放松模式 |
| /fast | 切换到快速模式 |
| /blend | 将多个图片混合 |
| /prefer remix | 切换到混合模式 |
| /help | 查看帮助信息 |
| /info | 查看基本信息,如订阅状况、工作模式等 |
| /stealth | 切换到隐身模式 |
| /public | 切换到公共模式 |
| /subscribe | 管理订阅 |
| /prefer option set | 创建自定义变量 |
| /prefer suffix | 指定要添加每个提示末尾的后缀 |
| /prefer option list | 列出之前设置的所有变量 |
| /show | 结合任务ID生成原图片 |
| /describe | 图生文功能,根据上传图像,生成四种可能的提示词(prompt) |
| /shorten | 分析提示词中关键字 |
| 放大/微调/重复图形命令 | U1/U2/U3/U4 放大按钮,V1/V2/V3/V4微调按钮,”重复”按钮 |
| 放大后图像的变化、拉远、平移 | |
| Vary(Region) | 局部重绘按钮 |
| 使用第三方插件insightface进行换脸 |
/imagine: 通过提示词生成图片或者通过垫图和提示词生词图片
最基本的指令,用于生成图片,prompt后面加描绘词
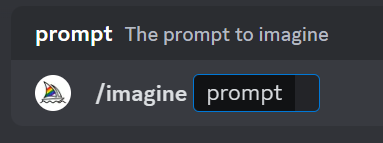
该指令还可以用来实现垫图功能,可以使用指定图像作为提示的一部分来影响出图的构图、风格和颜色
所谓的垫图就是找到一张合适的图片作为参考底图,配上文字描述,得到与图文相符合的图像,可以快速高效得到想要的效果图
具体垫图操作流程为,点击对话框的“+”图标,上传要作为参考的图片
鼠标停留在对话框,敲回车键(Enter)上传图片,很多朋友没操作这一步;
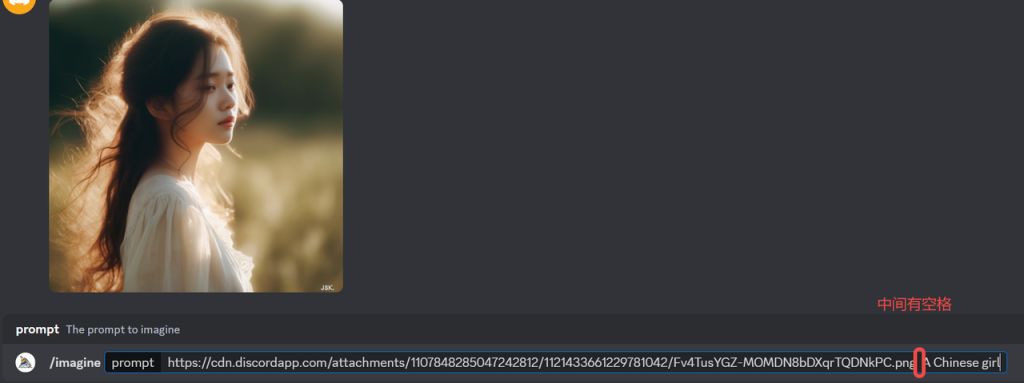
输入 /imagine 基础指令,将图片拖拽到对话框中,成功后会显示该图片的链接。图片链接最后,记得空一格,再开始敲关键词,完成后发送
/settings:查看当前Midjourney机器人默认设置
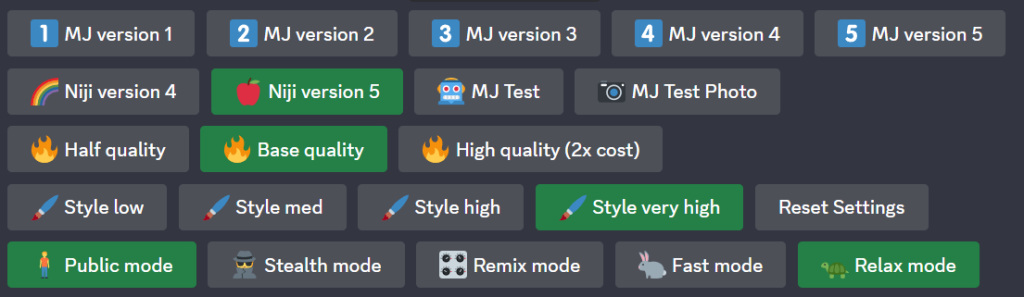
- 第一行是Midjourney 版本。目前有版本 1, 2, 3, 4, 5,5.1,5.2,5.3,最新的版本是v5.3。版本数字越大,图片分辨率更高,Midjourney对提示词的理解力更强,图片的细节处理也更好
- 第二行是Niji 模式,Niji是指图片是二次元风格,更适合制作动漫类图片。目前有Niji version 4,5
- 第三行是图片的质量参数。质量越高,图片效果越好。这里的质量是指画面的细腻程度,质量越好消耗的资源(GPU时间)越多。默认的是Base quality
- 第四行:风格参数,low, med, high, very high四种模式。这四种模式主要体现在风格的变化上,使用相同提示词的前提下,Style high创作图片的风格上变化更多,Style low则基本相同。默认的是Style med
- 第五行:输出模式:
- Public mode是切换到公开模式,所有人都可以看到你生成的图片
- Stealth mode是切换到隐私模式,只有自己可以看到。仅限于专业套餐的用户(60美金每月)
- Remix mode是切换到混音模式,可以局部风格进行调整
- Fast mode是切换到快速模式,即可以快速出图
- Relax mode是切换到放松模式,出图较慢。这个模式比快速模式出图慢,仅限于标准套餐用户(30美金每月)和专业套餐用户(60美金每月)。这两个套餐用户在使用完快速模式后会自动切换到放松模式
/ask:获取问题答案
过程中有不懂的问题,可以通过/ask指令的方式提问
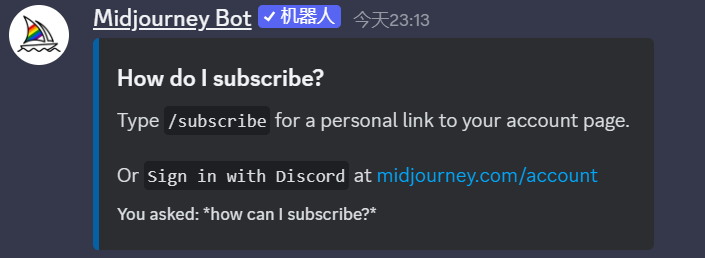
/relax:切换到放松模式
relax模式也就是慢速模式,生成图的时候比较慢,相反是/fast快速模式
/fast:切换到快速模式
即快速模式,生成图的时候比较快,相反是/relax模式
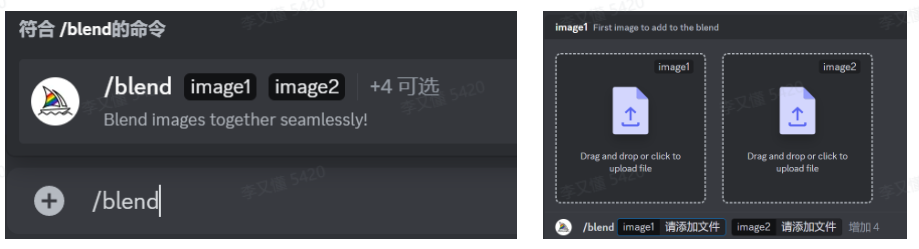
/blend:将多个图片混合
将多张(两张到五张)图混合在一起,变成一个新的图片。请注意,命令/blend不适用于添加提示词。要同时使用文本和图像提示,则需要使用命令/imagine。如果新合成的图片想获得最好效果,需要让上传的几张图片长宽比相同
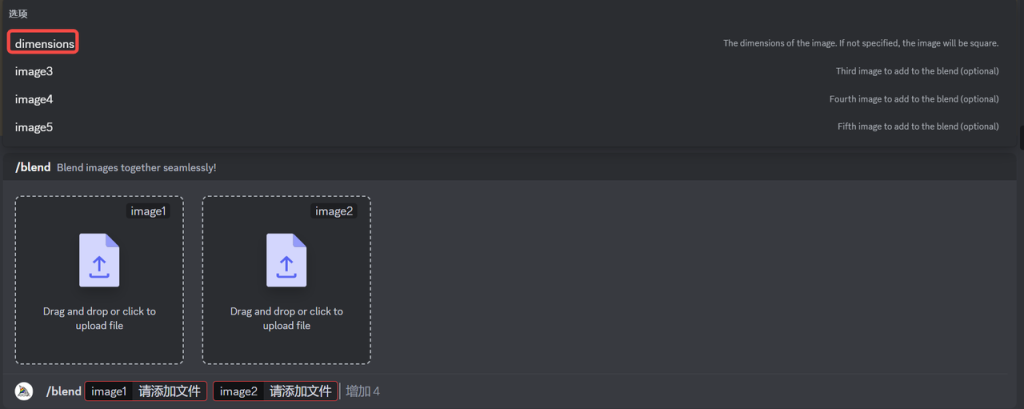
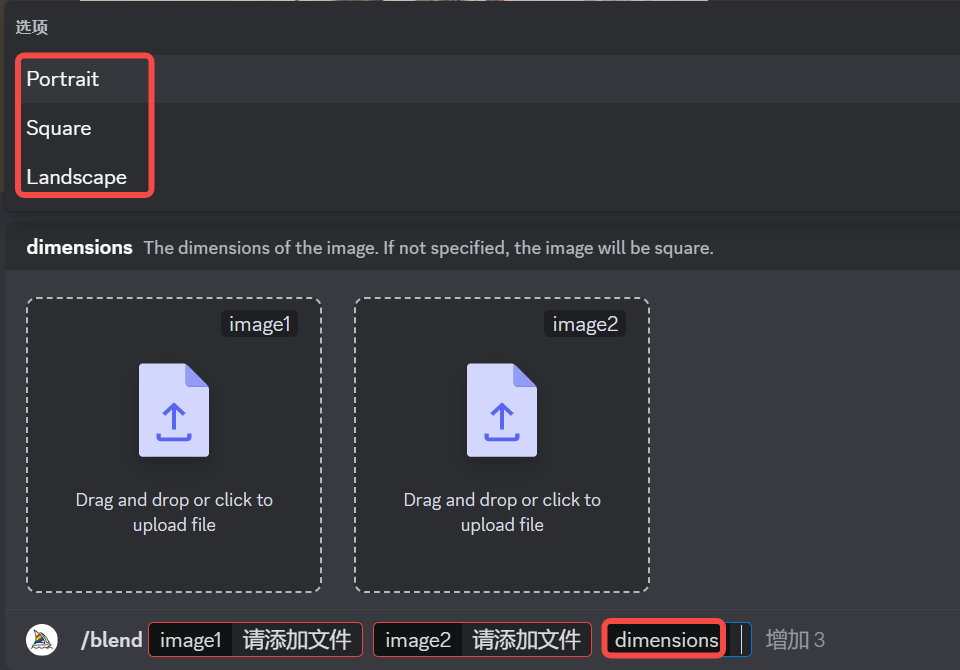
混合图像的默认宽高比例为 1:1,但也可以使用可选的 dimensions 字段。选择 square(方形)1:1,portrait(竖版)2:3 还是 landscape(横版)3:2
/prefer remix:切换到混合模式
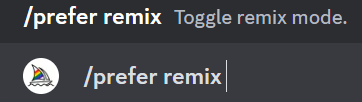

打开remix模式后,可以在原本图片的提示词基础上进行更改相关的提示词或者参数等。可以简单认为,Remix 模式将基于原始图像,合入新的提示,从而实现局部更改图片的效果
具体操作是,先打开remix模式,找到一张生成的图片,在四宫格图的情况下,点击V1/V2/V3/V4,或者点击单图修改,会有一个弹窗出现,里面的提示词是原本的提示词,可以在这个基础上进行修改提示词
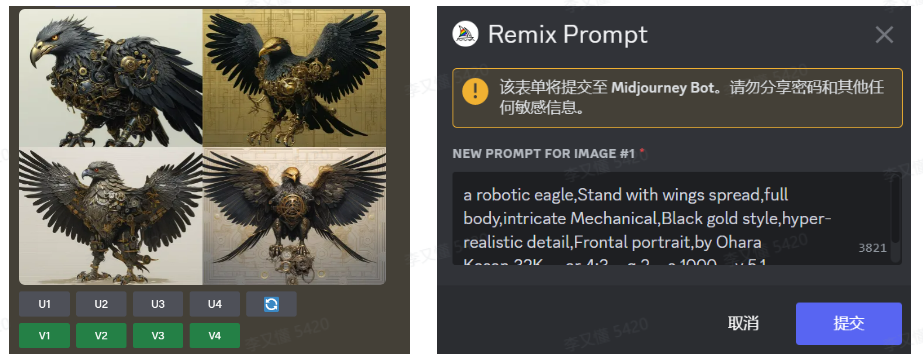
如果需要关掉remix模式,就直接重新输入一遍即可

/help:查看帮助信息
和很多工具软件一样,/help就是打开一些帮助项,这个我们少得到。不过如果你刚开始使用Midjourney,这是个不错的引导提示
/info:查看基本信息,如订阅状况、工作模式等
查看一些订阅信息,工作模式之类
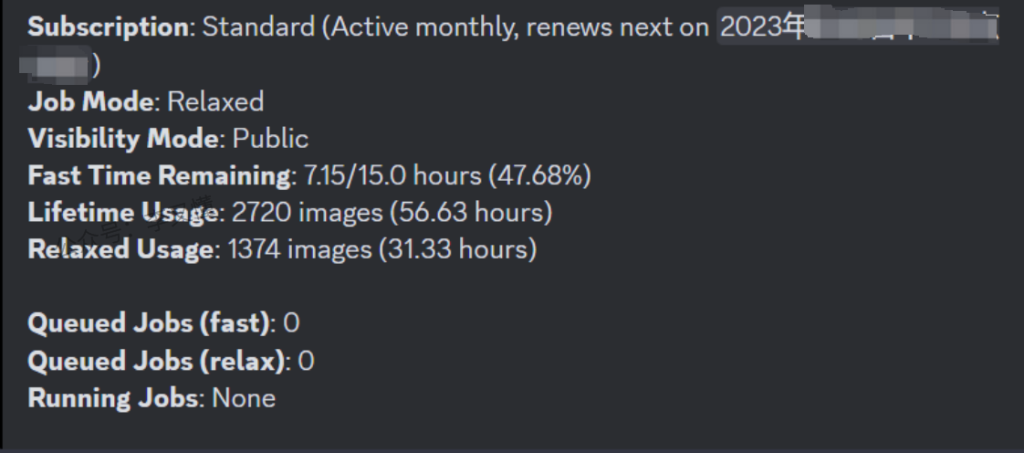
Subscription: 显示订阅了哪个套餐以及您的下一个续订日期。
Job Mode: 显示当前是处于Fast 还是 Relaxed Mode。
Visibility Mode: 显示当前是处于公开模式还是隐身模式。隐身模式仅限于专业套餐用户(60美金每月)
Fast Time Remaining: 显示当前套餐周期还剩余多长的快速出图时间(剩余时间百分比)。注意,快速出图时间每月会重置一次,不叠加,如果没有用完就浪费了
Lifetime Usage: 显示从注册该账号起,生成的总图片张数,包括初始四宫格图片、放大图片、变体图片、混合图片等
Relaxed Usage: 显示当月放松模式的使用情况。每个月会重置
Queued Jobs: 显示所有排队等待运行的任务,最多可以同时排队七个任务
Running Jobs: 显示当前正在运行的所有任务,最多可以同时运行三个任务
/stealth:切换到隐身模式
隐身模式,即只有自己看得到生成的图像。仅限于专业套餐用户(60美金每月)
/public:切换到公共模式
公共模式,即大家都可以看到你生成的图像
/subscribe:管理订阅
查看订阅情况,注意保护订阅连接。
/prefer option set:创建自定义变量
定义变量 666 为 –ar 4:3, 之后就可以直接使用该变量,666即等于 –ar 4:3

/prefer suffix:指定要添加每个提示末尾的后缀
设置默认添加到每个提示末尾的后缀,设置后每次会自动在提示内容后面加上后缀。如果需要去除之前设置的后缀,只需要再次输入,内容为空保存就可以清空之前的后缀设置。注意后缀支持参数,不支持提示词
例如在后缀设置尺寸大小为16:9的图片格式
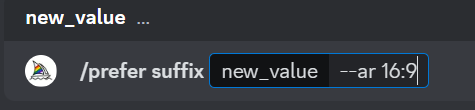
设置成功后,之后输入提示词的时候,这里的–ar 16:9 就会自动加入进来
prefer option list:列出之前设置的所有变量
将之前所定义的变量列出来

/show:结合任务ID生成原图片
结合自己生成的图片的ID,可复制相同的原图,注意/show 命令只适用于自己生成的图片。
比如复制下面的图片ID
Step1: 通过下载的图像时,找到想要复现的图片ID。图像 ID 是文件名的最后一部分复制
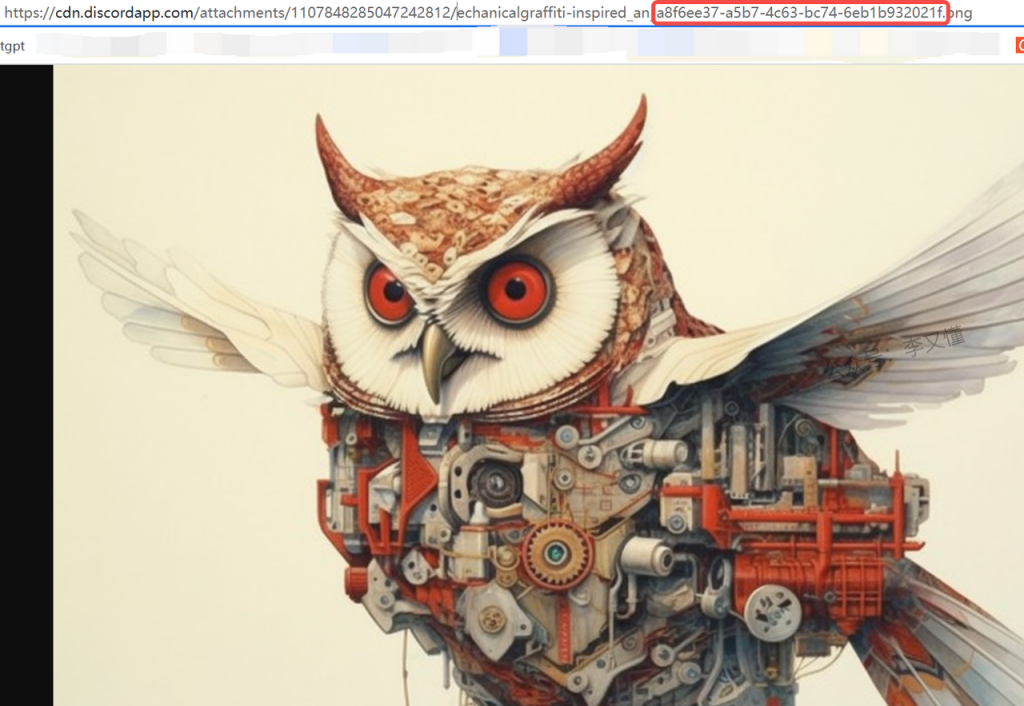
或者使用 Discord 表情符号的自动回复。在添加表情反应,输入envelope,点击信封表情✉️,Midjourney 机器人会私信给你图像信息,包括图像的种子编号和图像 ID。 注意,添加反应仅适用于你自己生成的图像
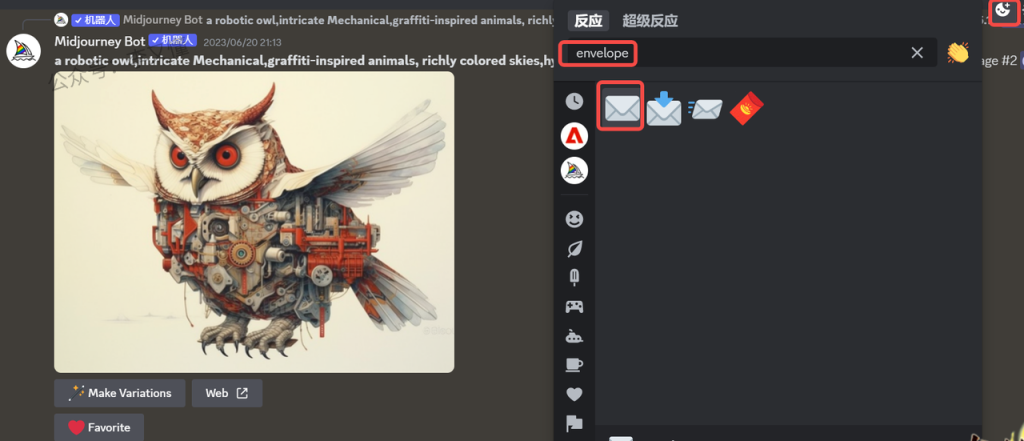
Step2: 复制上面的图片ID,粘贴到/show job_id 后面即可

Step3: 生成一样的图,如下所示。

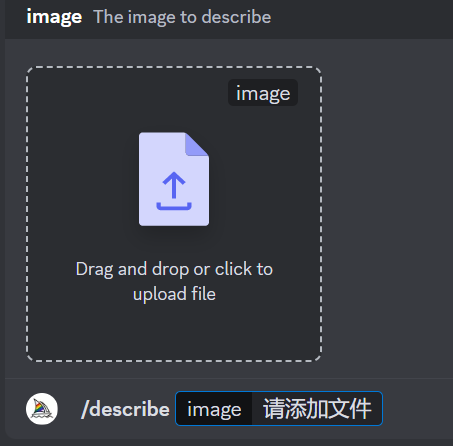
/describe: 图生文功能,根据上传图像,生成可能的提示词
通过上传的图片生成四种可能的提示词。上传文件之后,记得点击【Enter】发送
Midjourney会将图片转换为如下图所示的4个句子,点击句子下方的1、2、3、4,可将对应的句子转为图片。而且,可以在弹出的窗口直接修改描述语,再点击则可生成图片。

/shorten: 分析提示词中关键字
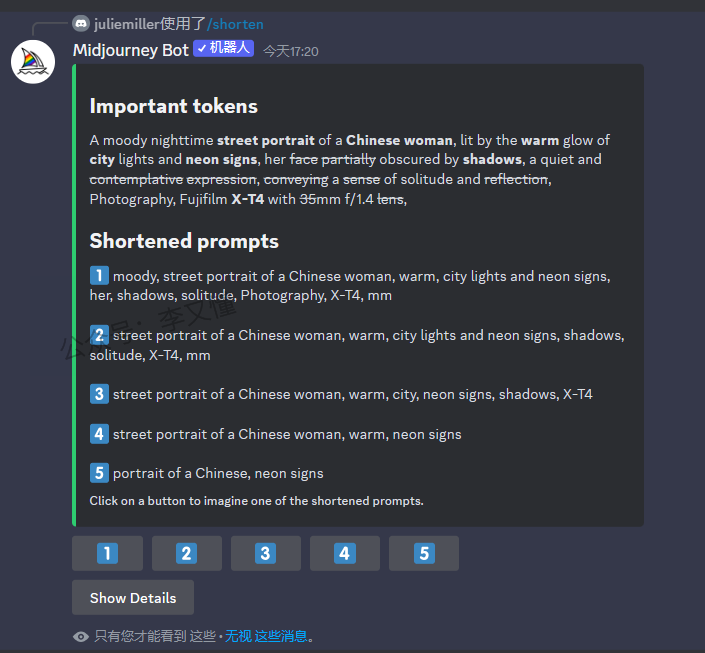
shorten是v5.2模型中新引入的命令,用于分析输入的提示词中的关键字,并生成更简洁的提示词
比如用下面的提示词,可以生成一张美女图片。但哪些才是真正影响出图的关键字呢?在真正知道哪些关键字后,今后就可以输入更高效的提示词来生成期望的图片了
“A moody nighttime street portrait of a Chinese woman, lit by the warm glow of city lights and neon signs, her face partially obscured by shadows, a quiet and contemplative expression, conveying a sense of solitude and reflection, Photography, Fujifilm X-T4 with 35mm f/1.4 lens, –ar 3:2 –v 5.2”

这时候可以用shorten命令分析刚才的提示词,分析出提示词中Midjourney认为重要的关键字,并给出5个更简短的提示词
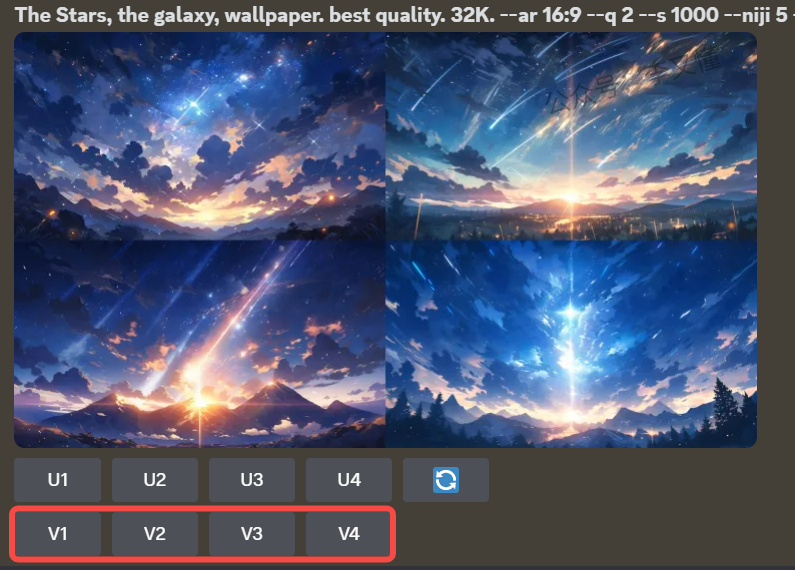
放大/微调/重复图形命令按钮:U1/U2/U3/U4 放大按钮,V1/V2/V3/V4 微调按钮,”重复”按钮
用户每输入一个全新的提示词,Midjourney初次会生成一个由4张低分辨率图像组成的图片网格。你可以在任何网格图像上使用U1/U2/U3/U4 放大按钮来放大所选图像。这样可以单独得到其中的某一张图片

在U1/U2/U3/U4 放大按钮下面,还有一组V1/V2/V3/V4 微调按钮,这些微调按钮用于生成与所选图像整体风格和构图相似的新四宫格。比如点击“V1“,则基于图1(左上角图)进行变化重新生成新的4张
在U1/U2/U3/U4 放大按钮的最右边还有一个”重复”按钮。这功能主要是用于对生成的四宫格图片每张都不满意或者还想多生成一些更满意的图片且还想用同样的关键词的情况。点击刷新按钮后,等待一小段时间就可以重新生成一批新图片,不会覆盖原图
记得放大图片、微调图片和重新生成一组图片都会消耗GPU资源
放大后图像的变化、拉远、平移命令按钮
Midjourney5.2版本中新增加了放大后图像的变化(Vary)、缩放(Zoomout)、平移(pan)等功能
具体示意操作如下:
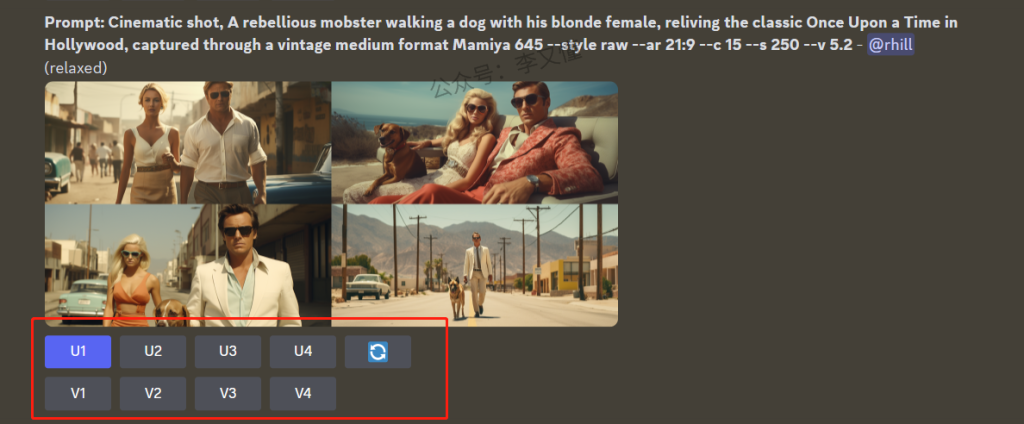
在生成四宫格图片之后,选出一张自己满意的图片进行放大(点击U1),生成如下图片
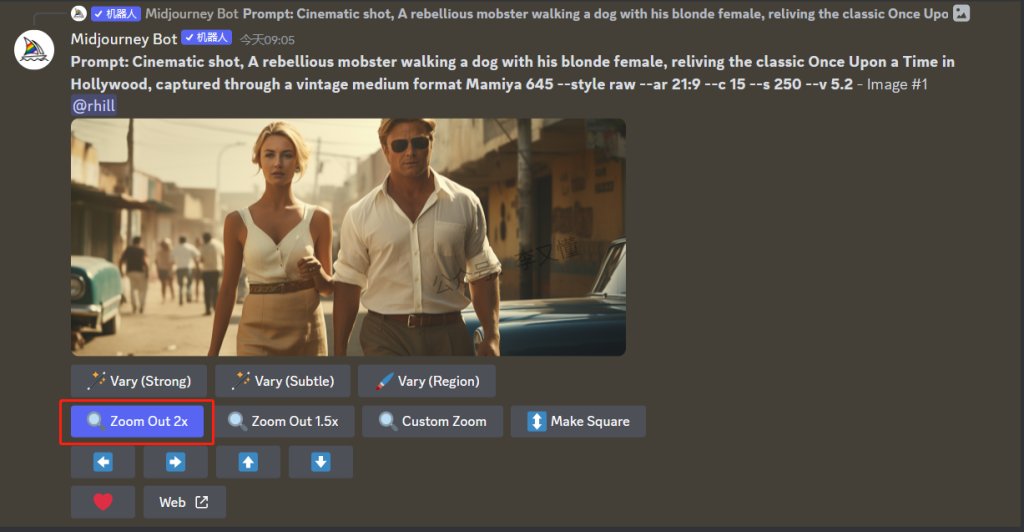
放大后的图像下面,你会看到三行按钮。
第一行是图片变化(Variation)命令按钮。该功能类似于4.3.19节中的V行(微调)按钮,可以根据这张大图的主题和风格,再次生成四张不同主题或主题变化的图像,有助于提高图像创意。该功能在v5.2版本中有两个按钮,分别是高变化(Vary strong)按钮和低变化(Vary subtle)按钮。高变化(Vary strong)让同一张图像生成 4 张变体图像差异更加明显。低变化(Vary subtle)模式让同一张图像生成 4 张变体图像差异会比较小
第二行是缩放(Zoomout)命令按钮。该功能最大的特点就在于可以将原始图像缩小到更小的尺寸的同时,保留原有图像的细节和质量。通过缩放输入图像并对其进行后光照处理,使其看上去像原图像的缩小版本。该功能在v5.2版本中有三个可选按钮,分别是两倍缩放( Zoom Out 2x),1.5倍缩放( Zoom Out 1.5x)和自定义缩放( Custom Zoom)。这些按钮可以让你调整原始场景的缩放比例。两倍缩放和1.5倍缩放会分别把原始场景外绘到原始图像的两倍和一倍半大小。自定义缩放会弹出一个文本框,允许在缩小时更改提示以及纵横比或精确缩放比例,精确缩放比例需要在1.0和2.0之间。如果输入了超过2.0的数字,Midjourney会给一个错误提示
下面是一个缩放前和缩放2倍后的图片对比:


第三行是平移(pan)命令按钮,也就是箭头按钮 ◀️ ▶️ 🔽 🔼。该功能用于移动视窗,生成指定方向的内容点击其中一个箭头,会将图片向那个方向扩展。例如点击了第一个向左的按钮,那么它就会在原图的左边添加更多的内容,增加的部分将占据原来图片的一半。如果此时是 Remix 模式(参考4.3.7节),还可以在扩展图片时更改提示。需要注意的是,当前不支持对平移后的图片进行变体操作,也就是说使用了平移功能就无法使用V按钮,生成的图片底部只有U按钮。如果在平移图像上缩小,其分辨率将减小到默认大小,并且不能在同一张图片上横向和纵向平移,也无法控制每次平移操作的平移量
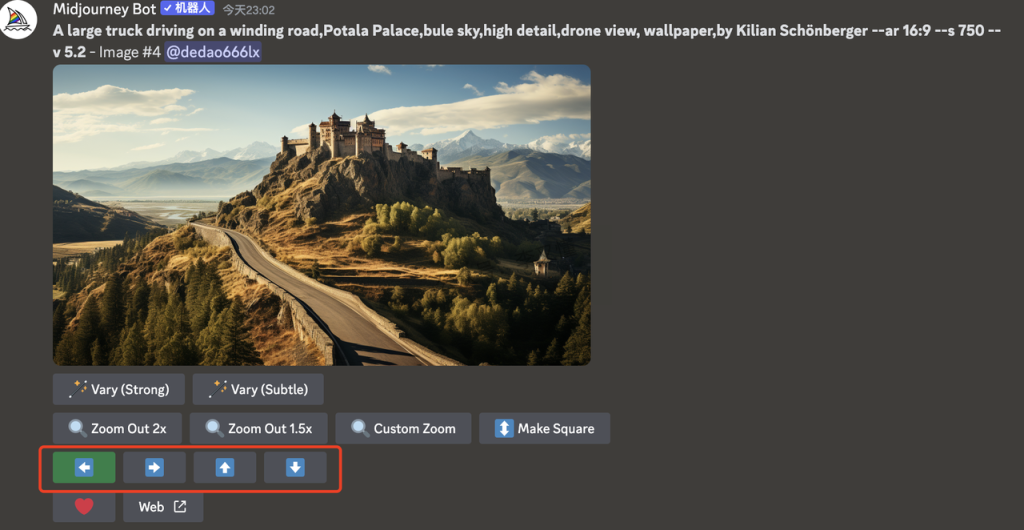
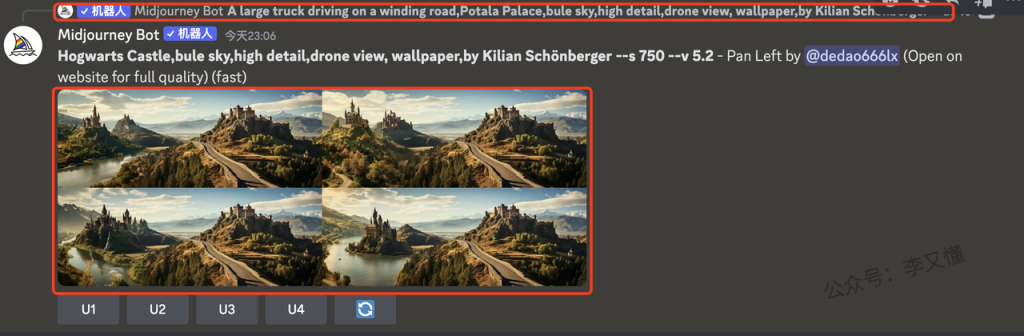
在设置中/settings 选择“重新混合(Remix)模式”,可以选择在扩展图像时更改 Prompt
技术要点:在扩展图片时更改提示词,尽量不要使用相同的prompt,否则只是普通的拼贴
Vary(Region)局部重绘按钮功能
当单张图片产出之后,下方会多出一个【 Vary(Region)】按钮
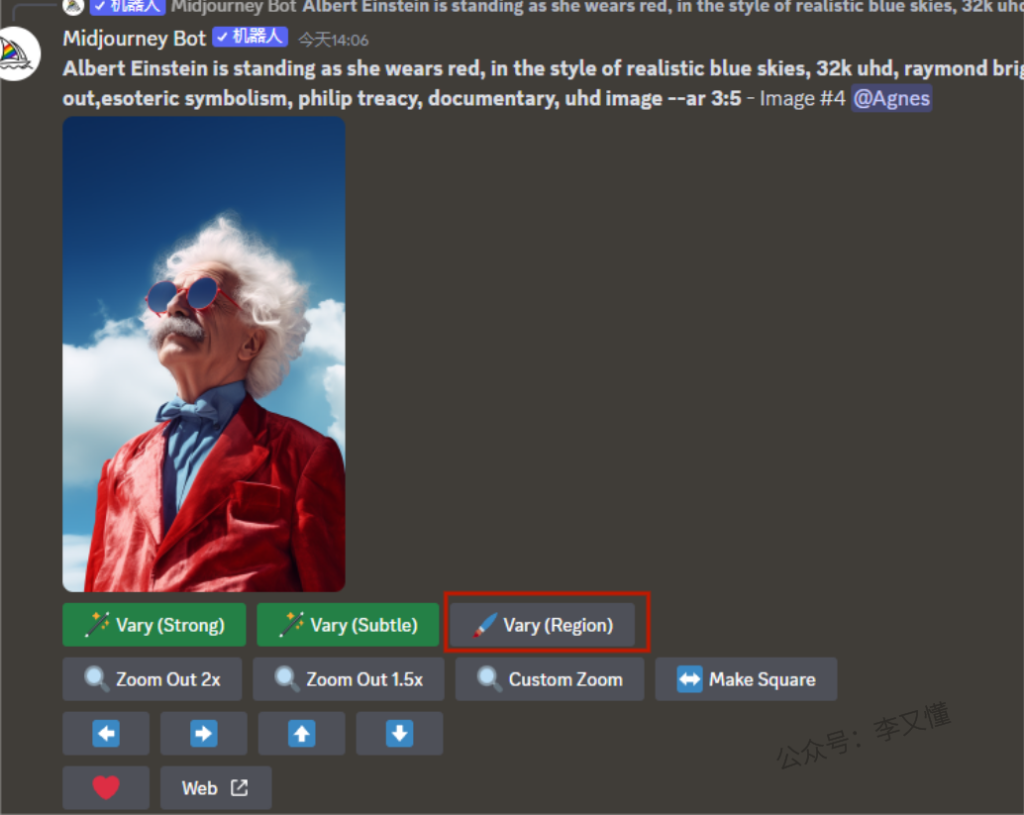
点击按钮后会跳转出这个二级页面,左上角的刷新按钮,是将你的画面框选内容重置,左下角的两款方形是框选,套索工具是更灵活的一种选择方式,选择之后,进行词语描绘,单击调整你要改变的地方,比方说变换衣服颜色,变换成狗头

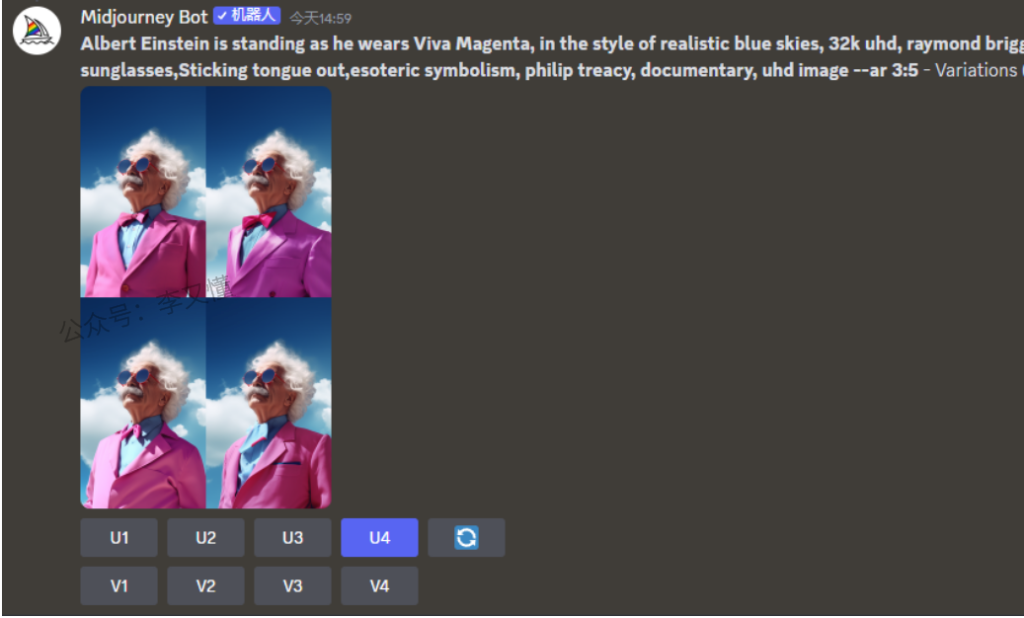
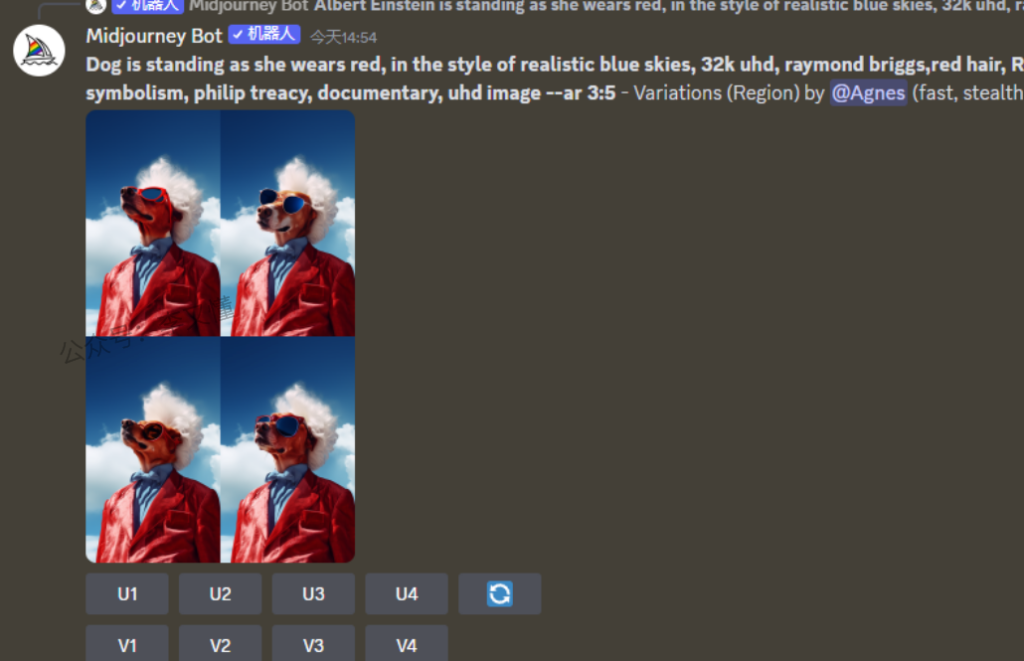
需要注意的是,此功能在图像的大区域(图像的20%到50%)上效果最好,该功能最好是在图片局部做一个微妙变化。改变提示符的时候需要尽可能符合逻辑,如果它是一个与图像更匹配的改变(在角色项部添加帽子),而不是一些非常不合适的东西(森林里的海豚)
使用第三方插件insightface进行换脸
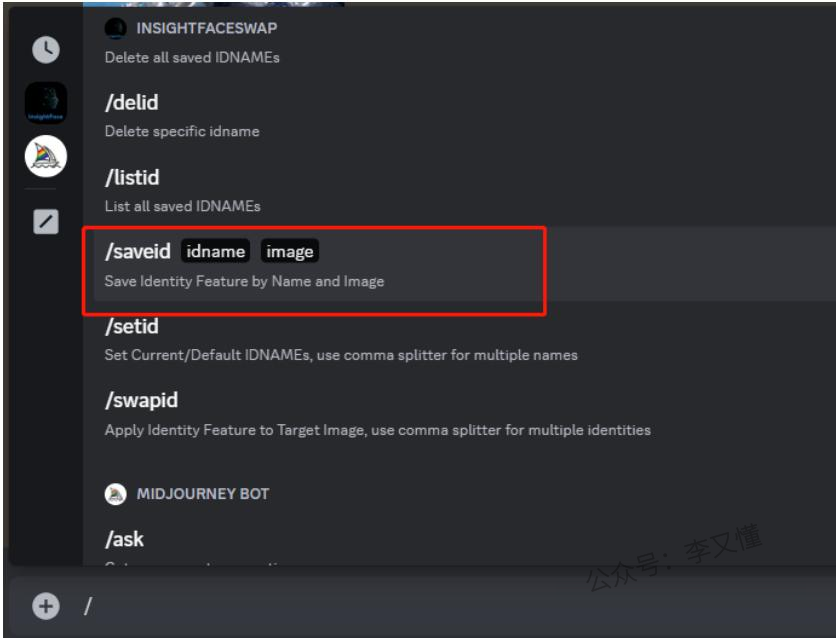
在生成AI人物图片中,如果对人脸有特定要求,比方说尽可能像某个人的脸,我们除了使用常规的垫图方法来生成图片,更高效的一个方法是使用第三方插件insightface。使用insightface之前,需要先把insightface添加到自己的discord服务器里,https://discord.com/oauth2/authorize?client_id=1090660574196674713&permissions=274877945856&scope=bot。
这样在菜单里就会出现/saveid这个命令了。
换脸操作主要分两步:
第一步,使用/saveid命令上传需要换成的目标照片,即真人照片。然后再输入一个名称用作标识。如果要使用 InsightFace 进行换脸,通常情况下,给到的脸部图片和需要换脸的图片人物的角度应该尽量一致。因为需要被换的图片中的脸通常都是正脸,所以需要换成的图片中最好是正脸,无遮挡的,比较清晰的。
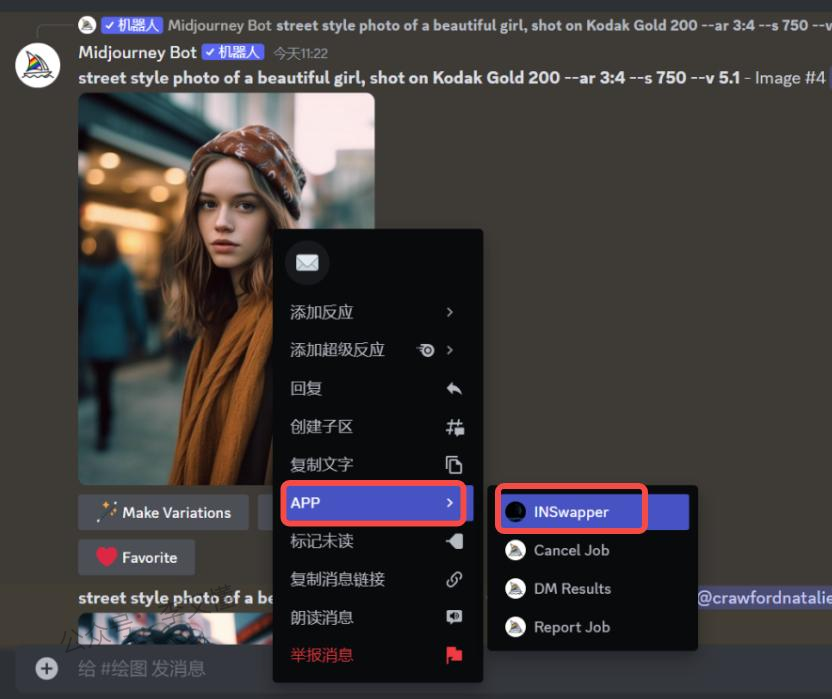
第二步,这时候在之前midjourney生成的图片中,点击右键的APP里的INSwapper菜单,就会将目标头像直接换到之前生成的图片中了。
InsightFace 和 Midjourney 的整合所带来的创造性的可能性是巨大的,但也存在一些限制:如果原脸和被替换的脸之间的面部特征差异过大,换脸的效果并不好。新版本已支持 ID 照片戴着眼镜,但是为了更好的效果,还是要确保面部清晰无遮挡,免费用户每天可以执行 50 条命令,付费用户享有更多命令和其他高级功能,比如付费用户拥有高保真模式的权益,换脸后的图片清晰度要更高。而免费版除了只能每天50点,还有每张图像替换一张脸的限制。如果一张图像中有多个人脸,则替换在图像中最大人脸,而付费版每张图像最多可以替换四张脸
5、MidJourney指令参数
- 纵横比(aspect ratios)–aspect 或–ar 改变生成图像的宽高比
- 混乱(chaos)–chaos 改变结果的多样性。较高的值会产生更多不寻常和意外的结果
- 负面提示(no)–no 负面提示。在提示词末尾加上 –no 可以让画面中不出现某些内容
- 生成质量(quality)–quality。值越高渲染时间越高,值越渲染时间越低
- 种子(seed)–seed。使用相同的种子编号和提示将产生相似的结束图像
- 停止(stop)–stop。 使用–stop参数在流程中途完成作业
- 平铺(tile)–tile。 该参数可用作重复拼贴的图像,以创建织物、壁纸和纹理的无缝图案
- 版本(version)–version 或–v。不同的模型擅长处理不同类型的图像
- 视频(video)–video。可用于创建图像生成过程的短片
- 风格化(stylize)–stylize 或–s。 参数会影响 Midjourney 的默认美学风格应用于任务的强度
- 重复参数(Repeat) –repeat 或 –r。用于重复画面的生成,可以一次性生成指定的次数,不必重复刷新
- 关键词权重 ::。让 Midjourney 单独考虑两个或多个单独的关键词概念,了解我们对某个关键词的倾向性
- 垫图权重 –iw。 找到一张合适的图片作为参考底图,配上文字描述,得到与图文相符合的图像,可以快速高效得到想要的效果图
- 并列提示词(Permutation Prompts) {}。允许使用单个 /imagine 命令快速生成提示词的变体
注意,参数的字母和后面的数字中间要保留一个空格,否则会提示报错
纵横比(aspect ratios)–aspect或–ar 调整图片的比例
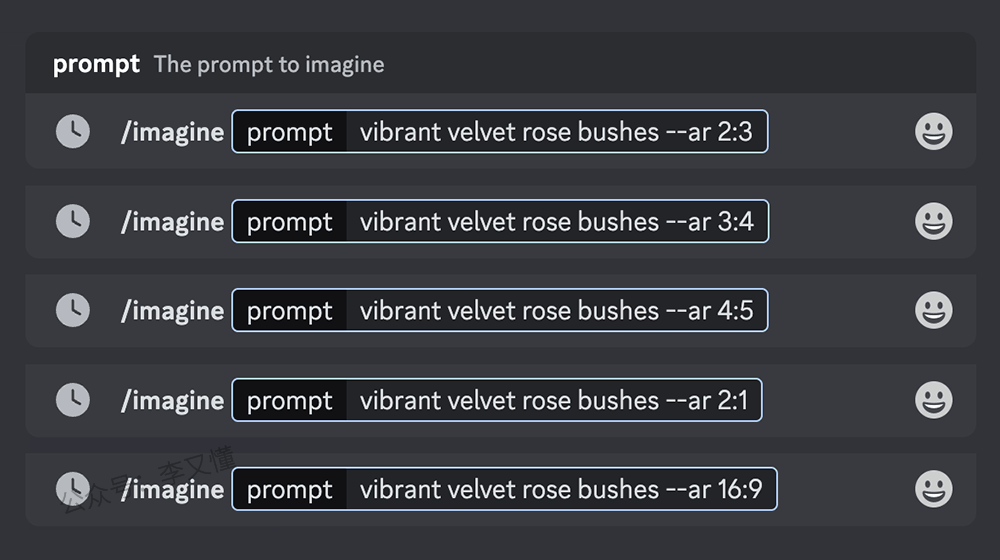
–aspect 或 –ar 参数用来改变生成图像的宽高比。宽高比是图像的宽度和高度的比率。它通常表示为用冒号分隔的两个数字,例如 7:4 或 4:3。
正方形图像的宽度和高度相等,宽高比就可以表示为 1:1 。图片尺寸不管是 1000*1000px 或者 1500*1500px,宽高比仍然是 1:1。笔记本电脑屏幕的比例可能为 16:10(显示器常见为 16:9)。宽度是高度的 1.6 倍。所以图像尺寸可以是 1600*1000px、3200*2000px、320*200px 等。
Midjourney 生成的图片默认的宽高比例为 1:1,微信头像的比例就是1:1。–aspect 或者 –ar 后面的比例必须使用整数。例如使用 139:100 而不是 1.39:1。宽高比会影响生成图像的形状和组成,并且图像使用放大器放大时,某些宽高比可能会略有变化。
常见的 Midjourney 宽高比如下所示:
• –aspect 1:1 默认的宽高比例。 • –aspect 5:4 常见的相框和印刷比例。 • –aspect 3:2 平面摄影中比较常见的比例。 • –aspect 7:4 靠近高清电视屏幕和智能手机屏幕。
在提示词中修改宽高比,只需要在提示词关键词末尾添加 –aspect <整数>:<整数> 或 –ar <整数>:<整数> 。
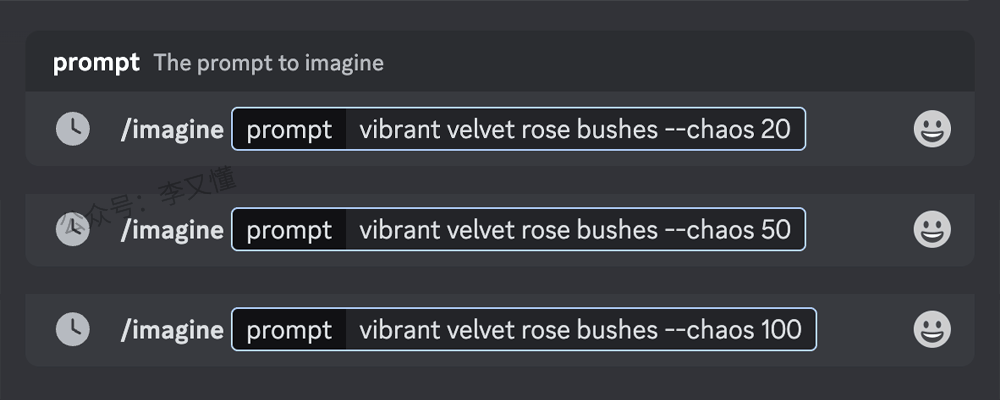
混乱(chaos)–chaos 改变结果的多样性。较高的值会产生更多不寻常和意外的结果
–chaos 或 –c 参数影响初始图像网格的变化程度。较高的 –chaos 值将产生更多不寻常和意想不到的结果和组合。较低的 –chaos 值具有更可靠、可重复的结果
–chaos 值的取值范围是:0–100 ,默认的 –chaos 值为 0
使用较低的 –chaos 值或不指定值,每次生成的初始网格图像,会略有不同。(风格、造型变化较小)
Prompt 关键词示例: /imagine prompt watermelon owl hybrid

使用极高的 –chaos 值,每次生成的初始网格图像,会产生最大程度的风格变化,产生更多意想不到的元素组合与艺术风格。(风格、造型变化最大)
Prompt 关键词示例:/imagine prompt watermelon owl hybrid –c 100

使用 –chaos 或 –c 参数,在 Prompt 关键词末尾添加 –chaos <数值> 或 –c <数值>
负面提示(no)–no 负面提示
在提示词末尾加上 –no 可以让画面中不出现某些内容;比如提示词关键词后面添加 –no plants ,Midjourney 会尝试从图像中去除植物
生成质量(quality)–quality. 值越高渲染时间越高,值越渲染时间越低
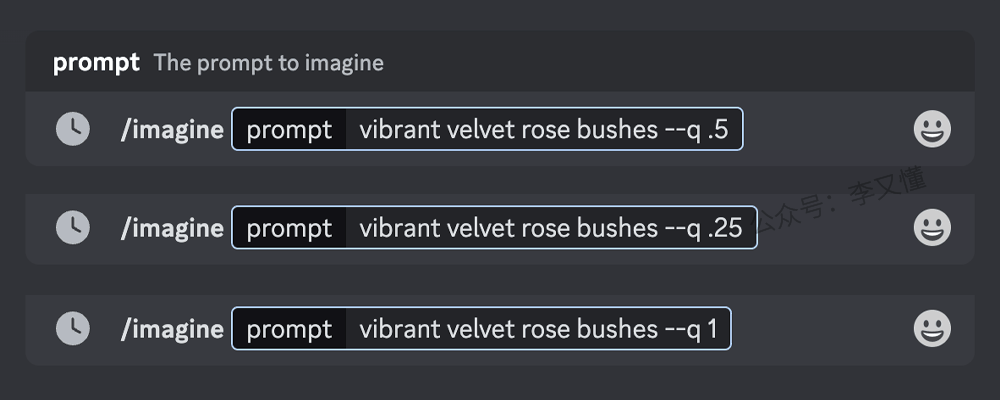
–quality 或 –q 参数更改生成图像所花费的时间。设置更高的质量会处理和生成更多的图像细节,所需的时间也更长,这也意味着图像的生成过程会消耗更多的 GPU 分钟数(消耗更多会员时长)。
默认的 –q 值为 1。–q参数可以设为这些值——0.25/0.5/1/2。–q 仅影响初始图像生成,且适用于模型版本 1、2、3、4、5 和 niji。 注意,质量设置不会影响最终生成图像的分辨率。
另外,更高的 –q 质量设置不一定更好。有时较低的 –q 质量设置可以产生更好的效果,具体还要取决于需要创建的图像。比如造型偏简单和抽象的画面适合使用较低的 –q 质量设置 ,而类似建筑等的图像就需要更多的细节,较高的 –q 质量值可以提升这些图像的观感。所以,只要根据需求,选择最适合图像类型的设置即可。
使用 –quality 或 –q 参数,在 Prompt 关键词末尾添加 –quality <数值> 或 –q <数值> 。
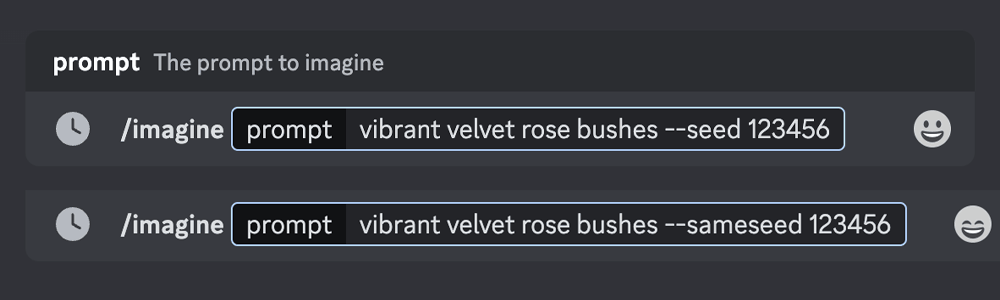
种子(seed)–seed. 使用相同的种子编号和提示将产生相似的结束图像
用过 Midjourney 的同学会发现在发送提示词后,Midjourney 最开始的图像里会有一个非常模糊的噪点团 ,然后逐渐变得具体清晰,而这个噪点团的起点就是“Seed” 种子编号是为每个图像随机生成的,但可以使用 –seed 或 –sameseed 参数指定。使用相同的种子编号和提示将产生相似的结束图像
–seed 接受的整数范围为 0–4294967295 且 –seed 的值仅影响初始图像网格。如果不指定种子,Midjourney 将使用随机生成的种子编号,每次使用 Prompt 关键词时都会生成多种选项
–seed 值创建一个大的随机噪点画面,应用于初始网格中的所有图像。当指定 –sameseed 时,初始网格中的所有图像都使用相同的起始噪点画面,并将生成非常相似的生成图像。–sameseed 接受整数 0–4294967295,且–sameseed 仅与模型版本 1 、2 、3 、test 和 testp 兼容。所以平时大家在v5或者v5.1中是用不到–sameseed选项
查找图像的种子编号可以使用 Discord 表情符号中的 ✉️ 信封表情符号做出反应,在 Discord 中找到图像的种子值。此处的操作方式与2.16中获取图像 ID 一致
使用 –seed 或 –sameseed 参数,在提示词末尾添加 –seed <种子值> 或 –sameseed <种子值>
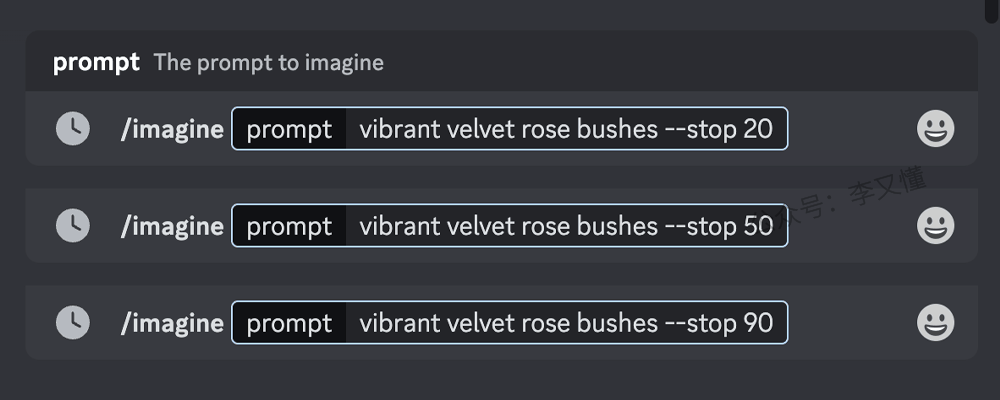
停止(stop)–stop. 使用–stop参数在流程中途完成作业
使用 –stop 参数在流程的中途完成图像。以较早的百分比停止图像生成,会产生更模糊、细节更少的生成结果。
–stop 可以接受的取值范围:10–100,默认值为 100。–stop 在放大图像时不起作用。
停止参数的使用效果对比

使用 –stop 参数,将 –stop <数值> 添加到 Prompt 关键词的末尾。
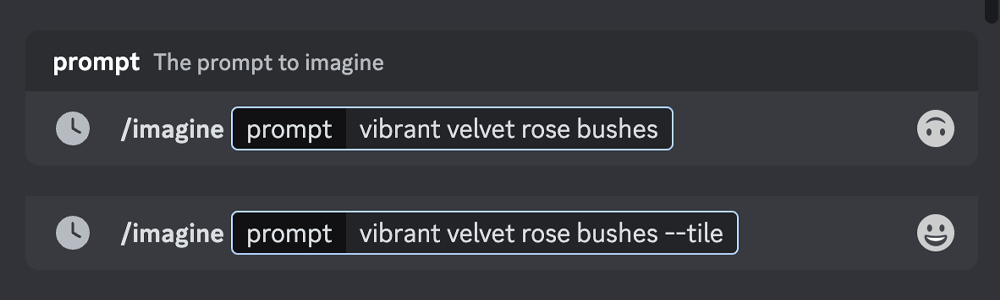
平铺(tile)–tile. 该参数可用作重复拼贴的图像,以创建织物、壁纸和纹理的无缝图案
–tile 参数生成可用作重复拼贴的图像,用来创建布料、壁纸和纹理的无缝贴图图案。–tile 适用于模型版本 1 、2 、3 和 5 。–tile 只生成一个可重复的图块
使用 Midjourney V5 模型
提示词:scribble of moss on rocks –v 5 –tile 提示词:watercolor koi –v 5 –tile

使用平铺参数,直接将 –tile 添加到关键词的末尾
版本(version)–version 或–v。不同的模型擅长处理不同类型的图像。
Midjourney 定期发布新模型版本以提高效率、一致性和质量。默认为最新型号,但可以使用–version 或–v 参数或使用/settings 命令并选择型号版本来使用其他型号。不同的模型擅长处理不同类型的图像。–version 接受值 1、2、3、4 和 5,5.1,5.2,6。–version 可以缩写–v
您可以使用–version 或–v 参数或使用/settings 命令并选择模型版本来访问更早的 midjourney 模型。不同的模型擅长处理不同类型的图像。例如:/imagine prompt vibrant California poppies –v 1
另外还有一个叫Niji的模型。该模型是 Midjourney 和 Spellbrushniji 之间的合作,经过调整可以制作动画和插图风格。该模型对动漫、动漫风格和动漫美学有更多的了解。一般来说,它在动态和动作镜头以及以角色为中心的构图方面表现出色。只需要在提示词的末尾添加 –niji。例如:/imagine prompt vibrant California poppies –niji
需要注意的是,Niji 不支持–stylize 参数。使用/settings 命令并选择 Style Med 重置为所有–niji 提示的默认样式设置
使用版本或测试参数的时候,只需要将–v 1, –v 2, –v 3, –v 4, –v 5,– v5.1, –v 5.2, –v 6,–test, –testp, –test –creative,–testp –creative 或添加–niji 到提示的末尾

或者从对话框中键入/settings并选择相应的版本即可

视频(video)–video. 可用于创建图像生成过程的短片
使用该–video 参数创建正在生成的初始图像网格的短片。使用信封表情符号对完成的工作做出反应,Midjourney 将视频链接通过私信发送
–video 仅适用于图像网格,且只适用于模型版本 1、2、3、test 和 testp。由于视频功能只能适用于较早期版本,生成的图片质量跟新本版没法比,所以很少用到,大家可以根据自己的需求去尝试。
获取视频链接的操作方式与2.16中获取图像 ID 一致
提示示例:/imagine prompt Vibrant California Poppies –video
① 添加–video 到提示的末尾;
② 任务完成后,单击添加反应;
③ 选择信封表情符号;
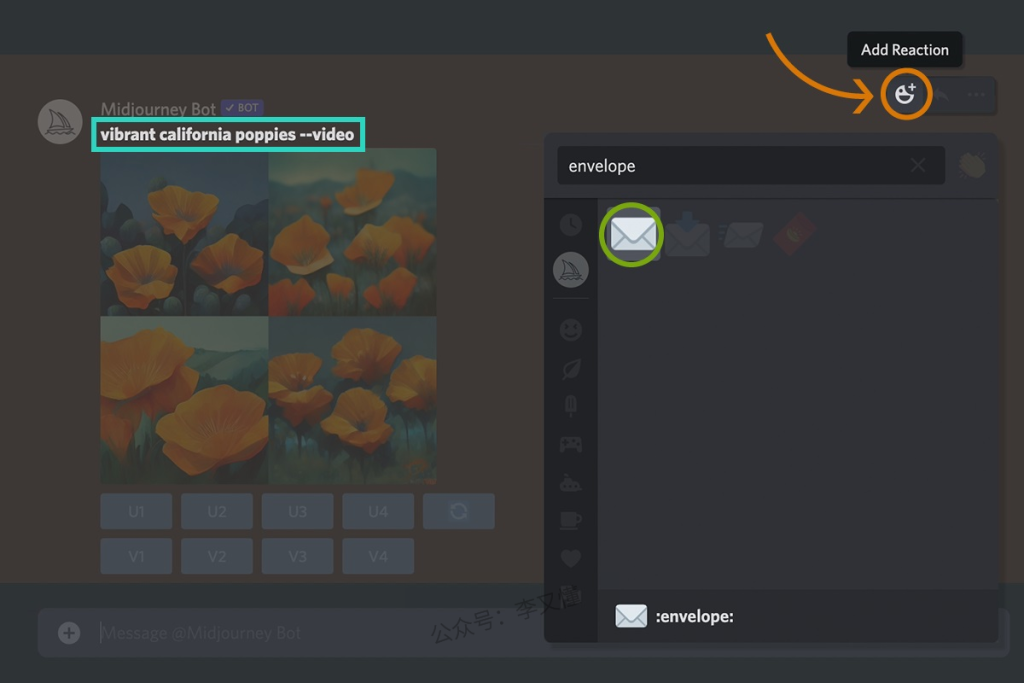
或者直接将 –video 添加到 Prompt 关键词的末尾
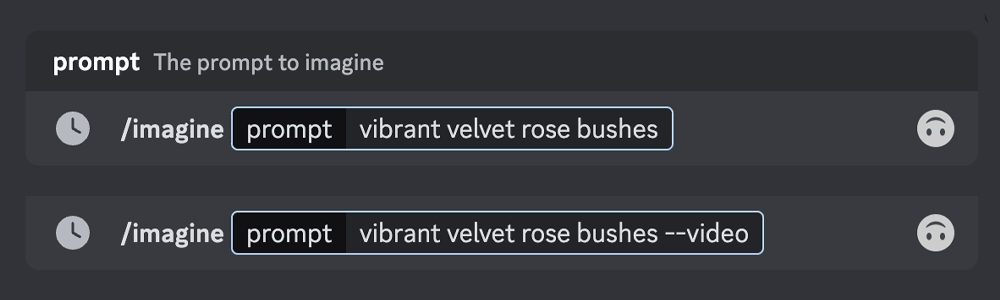
风格化(stylize)–stylize 或–s。该参数会影响 Midjourney 的默认美学风格应用于任务的强度
Midjourney 机器人经过训练,可以生成更偏向于具有艺术感的色彩、构图和形式的图像。 –stylize 或 –s 参数会影响此训练效果的应用强度
低风格化参数值生成的图像会更加匹配提示词,但艺术性较弱。高风格化参数值创建的图像非常具有艺术感,但与 提示词的匹配度会减弱。–stylize 的默认值为 100,并且在使用默认模型版本时接受 0-1000 的整数值。

不同的 Midjourney 版本模型具有不同的风格化范围
V5 模型效果
提示词示例:/imagine colorful risograph of a fig –s 100

使用 stylize 参数的时候,只需要添加–stylize < value >或–s 到提示的末尾
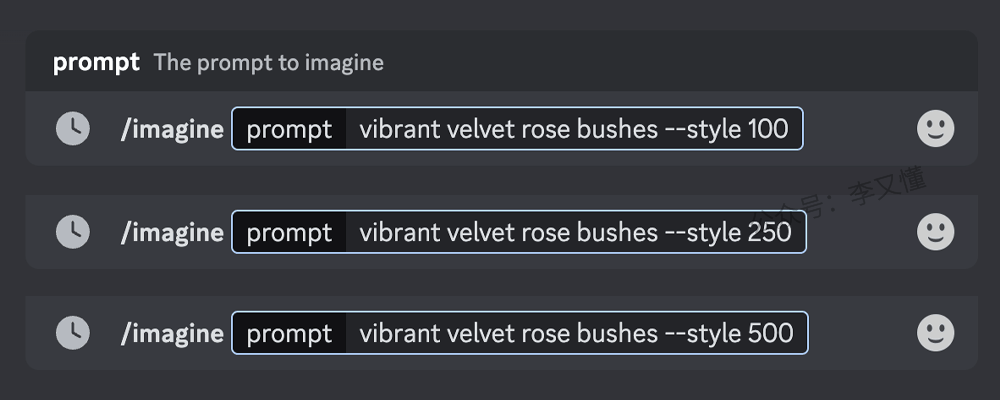
或者从对话框中键入/settings并选择相应的风格化值

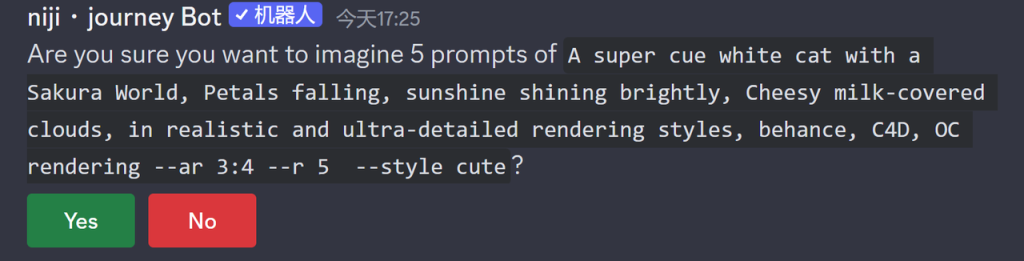
重复参数 –repeat 或 –r。用于重复画面的生成,可以一次性生成指定的次数,不必重复刷新
–repeat 或 –r 参数可以多次运行一个图像生成任务。将 –repeat 与其他参数结合使用(例如 –chaos )以加快视觉探索的速度。
需要注意的是,–repeat 仅适用于标准套餐用户(30美金每月)和专业套餐用户(60美金每月)且只能在 /fast 快速 GPU 模式下使用
此外,标准套餐用户(30美金每月)可以用 –repeat 重复生成的任务数量为2~10。至于专业套餐用户(60美金每月),可以用 –repeat 重复生成的任务数量为2~40
还有一点需要注意的是,在 –repeat 任务图片结果上使用 重做按钮只会重新运行一次提示词
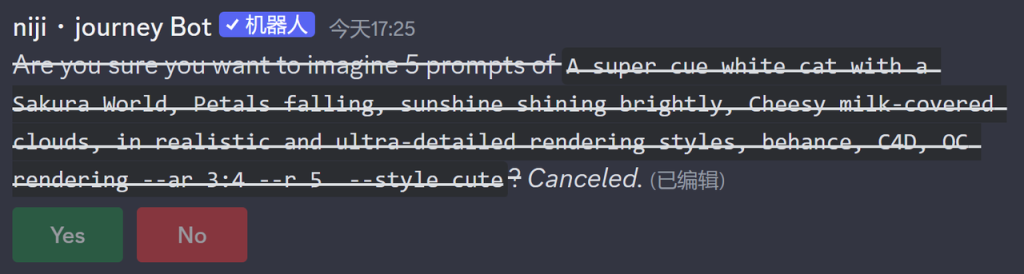
在提示词末尾添加 –r <N>,发送之后,MIdjourney会回复一条信息,确认是否需要重复。点击绿色【确认】按钮,等待生成N次,点击【否】则会取消这次指令
关键词权重 ::。让 Midjourney 分别考虑两个或多个单独的关键词概念,了解我们对某个关键词的倾向性
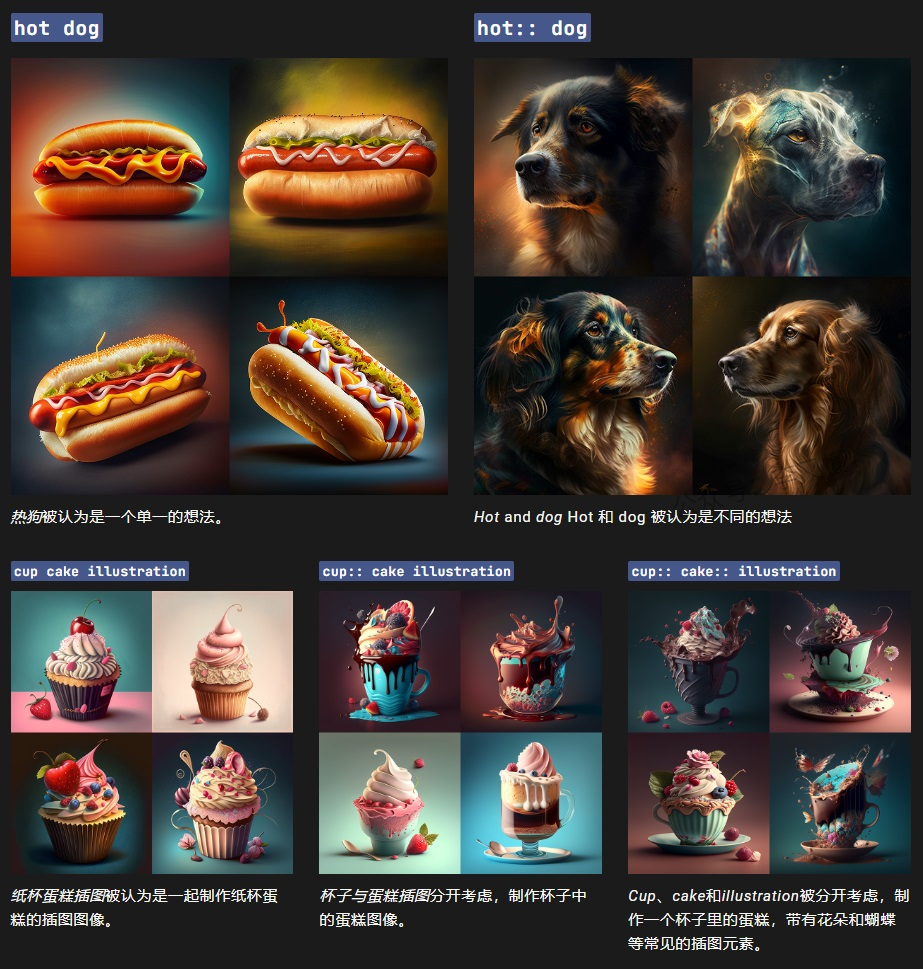
关键词权重是以分隔符 ::标注,主要有两个功能。一个是让 Midjourney 分别考虑两个或多个单独的关键词概念,另一个是让它了解我们对某个关键词的倾向性
先来看第一个功能——让 Midjourney 分别考虑两个或多个单独的关键词概念
::在提示词中添加双冒号向 Midjourney 表明它应该分别考虑提示词的每个部分。类似于拼音输入法中用单引号来隔开两个音节一样,比如xian和xi’an
如果还没有看明白,请看下面的示例。正常情况下,hot dog 所有单词都被考虑在一起,Midjourney 会根据hot dog 生成美味热狗的图像。如果将提示分成两部分,hot:: dog 则将两个概念分开考虑,从而创建温暖的狗的图片
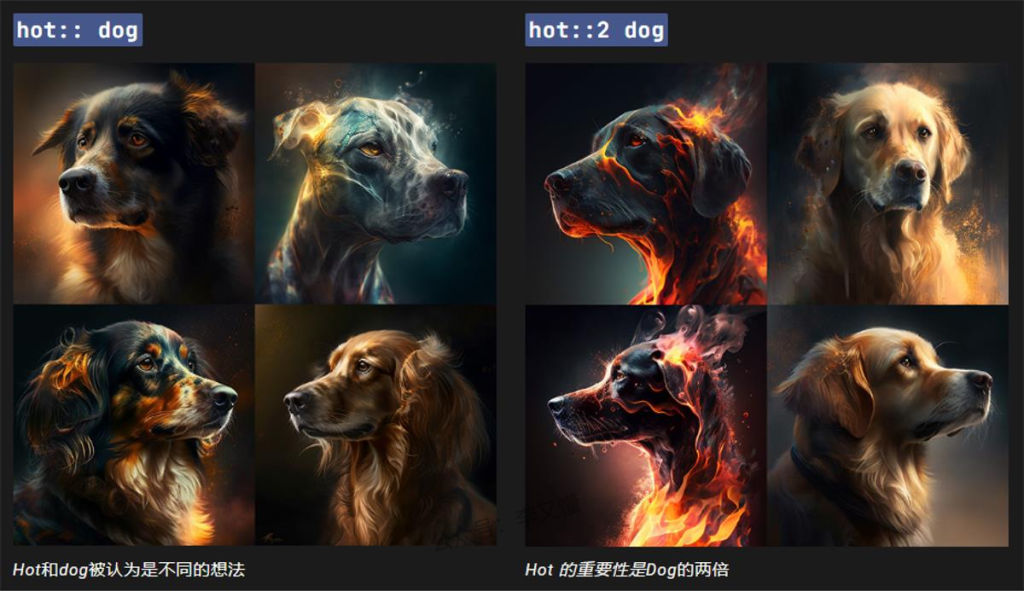
再来看第二个功能——让它了解我们对某个关键词的倾向性
当使用双冒号::将提示分成不同的部分时,在双冒号后添加一个数字,以分配提示的该部分的相对重要性。在下面的示例中,提示 hot:: dog 生成了一只热狗。将提示更改为使“热”hot::2 dog 一词的重要性是“狗”一词的两倍,从而产生了一只非常热的狗的图像!需要注意的是,V1, 2,3 只接受整数作为权重,V4 可以接受权重的小数位,非指定权重默认为 1
还有一个有趣的地方是,可给权重添加负数::-0.5,功能与–no一致。将负权重添加到提示中以删除不需要的元素,但所有权重的总和必须是正数

提示词权重具体使用方法如下:
- 默认权重为1,hot::1 dog::1;
- 如果想给某个提示词不一样的权重,比如A权重是B权重2倍,则可以写成A::2 B;
- 不同提示词之间数字如果同时按比例增大或者缩小,那权重比例不变。比如 hot::2 dog::2 = hot::4 dog::4,hot::1 dog::2 = hot::2 dog::4;
- 可给权重添加负数::-0.5,功能与–no一致。比如: lots of floweers::1 red::-0.5 = lots of flowers –no red;
- 整个描述词出现的权重必须为正,不能为负,所以当画面出现::-0.5的时候,权重1也必须写出来。比如 lots of flowers::1 red::-0.5是对的,但lots of flowers red:-0.5是错的
垫图权重 –iw。 找到一张合适的图片作为参考底图,配上文字描述,得到与图文相符合的图像,可以快速高效得到想要的效果图
在2.1中提到使用/image命令可以通过垫图的方式来达到以图生图的效果。
使用–iw参数可以改变参考图片的权重,图像权重数值可设置为:0.5,0.75,1,1.25,1.5,1.75,2,默认值为0.25。数值越高,参考图的影响越大。较高的–iw值适合对参考图风格及内容比较看重的操作,比如按照客户提供的参考图来生成图片
提示词示例:/image prompt flowers.jpg birthday cake –iw .5

使用垫图权限参数的时候,只需要在提示词末尾添加 –iw <数值>
并列提示词(Permutation Prompts),允许使用单个 /imagine 命令快速生成提示词的变体
并列提示词的功能主要是允许使用单个/imagine命令来快速生成提示词的变体
通过在提示词中的大括号” { } “内包含以英文逗号”, “分隔的选项列表,可使用这些选项的不同组合创建多个版本的提示词,比如/imagine prompt a {red, green, yellow} bird 创建并处理 3个提示词,分别为:
• /imagine prompt a red bird
• /imagine prompt a green bird
• /imagine prompt a yellow bird
单个提示词中可以在使用多组括号,比如:/imagine prompt a {red, green} bird in the {jungle, desert} 会创建并处理 4 个生成任务,分别为:
• /imagine prompt a red bird in the jungle
• /imagine prompt a red bird in the desert
• /imagine prompt a green bird in the jungle
• /imagine prompt a green bird in the desert
单个提示词中,括号内的选项集也可以嵌套在其他括号内,比如: /imagine prompt A {sculpture, painting} of a {seagull {on a pier, on a beach}, poodle {on a sofa, in a truck}} 会创建并处理 8 个生成任务,分别为:
• /imagine prompt A sculpture of a seagull on a pier
• /imagine prompt A sculpture of a seagull on a beach
• /imagine prompt A sculpture of a poodle on a sofa
• /imagine prompt A sculpture of a poodle in a truck
• /imagine prompt A painting of a seagull on a pier
• /imagine prompt A painting of a seagull on a beach
• /imagine prompt A painting of a poodle on a sofa
• /imagine prompt A painting of a poodle in a truck
使用并列关键词时,大括号内可以输入文本、图像提示、参数或提示权重、模型版本、尺寸比例等一切Midjourney能支持的指令参数。同时允许多个大括号同时出现,这意味着排列组合会增加更多的可能性
需要注意的是,并列关键词功能仅适用于使用 Fast 快速模式下的标准套餐用户(30美金每月)和专业套餐用户(60美金每月)专业套餐用户(60美金每月)。此外,Midjourney 将每个并列关键词的变体作为一个单独的任务处理,每个任务单独消耗 GPU 时长。 在开始生成之前在对话框中会收到一条确认消息
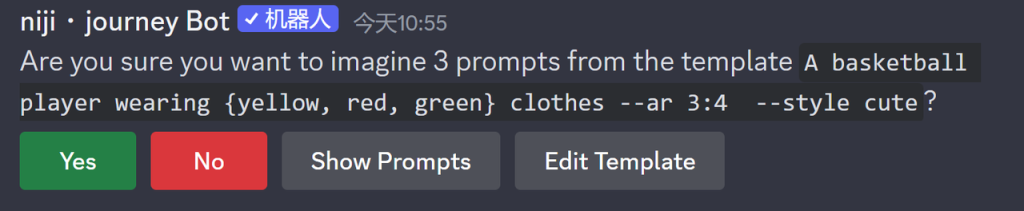
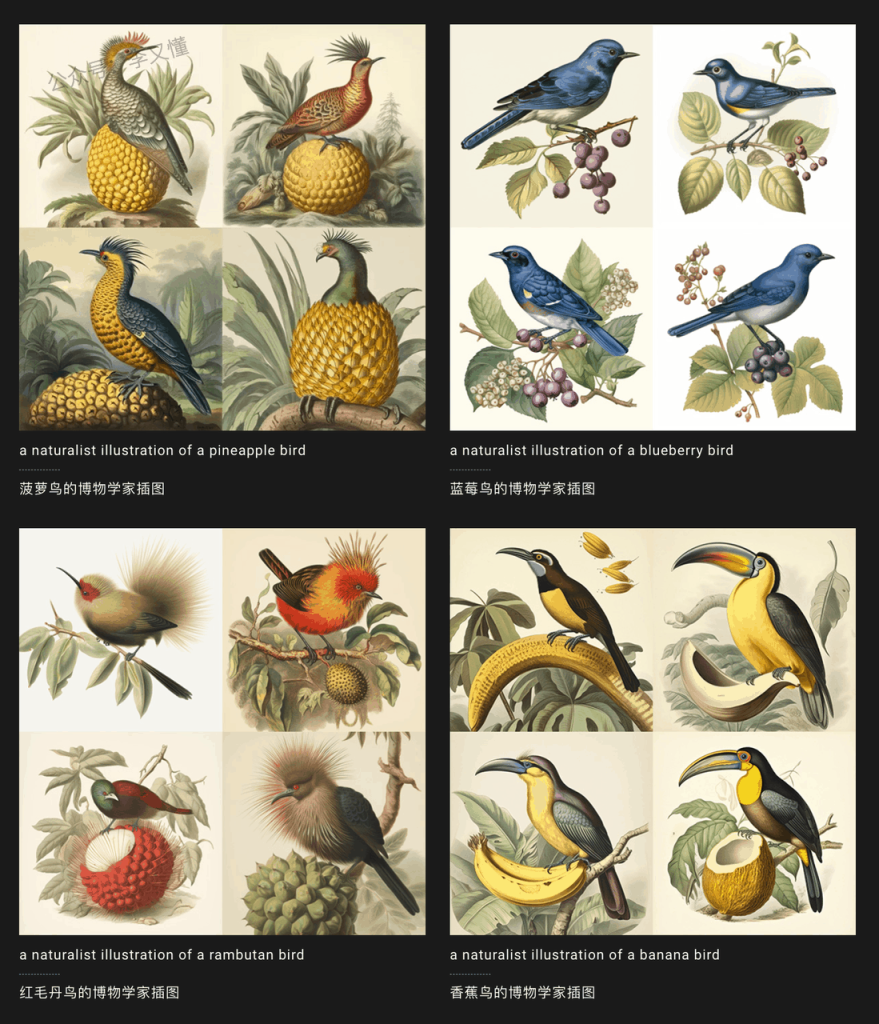
并列关键词示例如下, /imagine prompt a naturalist illustration of a {pineapple, blueberry, rambutan, banana} bird 将创建并处理 4 组图像
/imagine prompt a naturalist illustration of a fruit salad bird –ar {3:2, 1:1, 2:3, 1:2} 将创建并处理 4 组具有不同宽高比的图像

/imagine prompt a naturalist illustration of a fruit salad bird –{v 5, niji, test} 将使用不同的模型版本创建和处理 3 组图像

6、Midjourney 提示词学习
提示词的结构组成
基本提示词:一个基本的提示可以简单到一个单词、短语或表情符号。
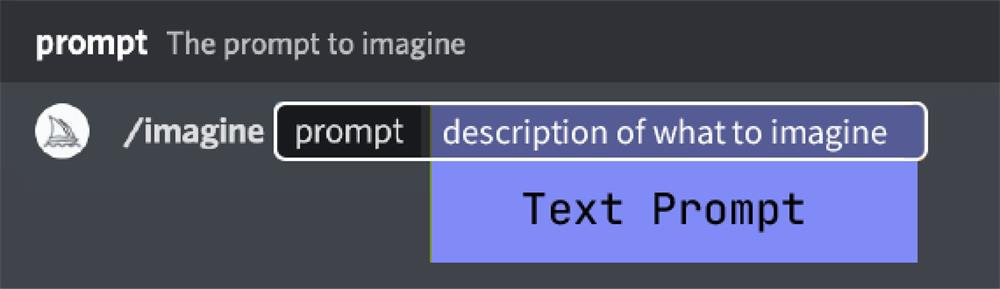
高级提示词:可以包括一个或多个图像链接、多个文本短语或单词,以及一个或多个后缀参数
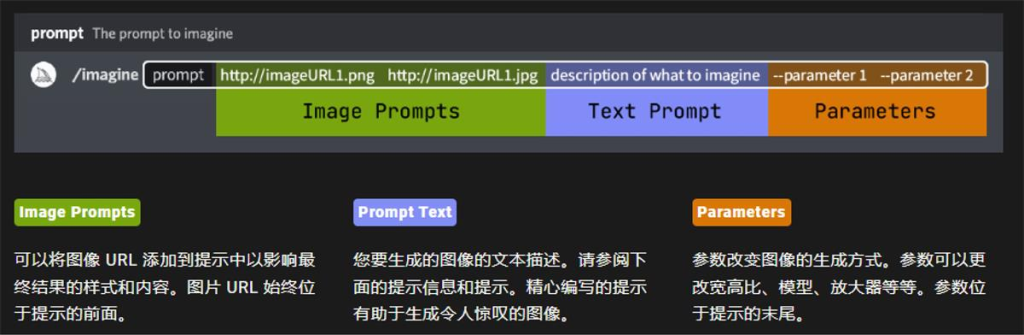
当我们想让midjourney画一张比较复杂场景的图片时,需要更长更精准的提示词。那如何写更长更精准的提示词呢?其实,写提示词也是有套路和模板的
关键词的常用结构是: 主题+环境+构图+风格+图像设定。
关键词的语法顺序
- 主题:人、动物、人物、地点、物体等。
- 媒介:照片、绘画、插图、雕塑、涂鸦、挂毯等。
- 环境:室内、室外、月球上、纳尼亚、水下、翡翠城等。
- 照明:柔和、环境、阴天、霓虹灯、工作室灯等
- 颜色:充满活力、柔和、明亮、单色、彩色、黑白、柔和等。
- 情绪:稳重、平静、喧闹、精力充沛等。
- 构图:人像、爆头、特写、鸟瞰图等。
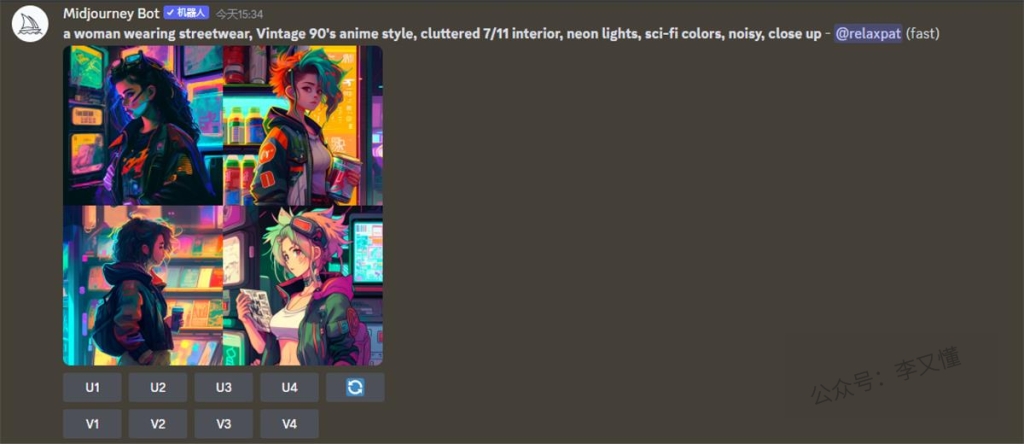
举个例子:
- 主题:a woman wearing streetwear(一个穿着街头服饰的女人)
- 媒介:Vintage 90’s anime style(90 年代的复古动漫风格)
- 环境:cluttered 7/11 interior(凌乱的 7/11 室内)
- 照明:neon lights(霓虹灯)
- 颜色:sci-fi colors(科幻色彩)
- 情绪:noisy(喧闹)
- 构图:close up(近距离)
完整关键词:a woman wearing streetwear, Vintage 90’s anime style, cluttered 7/11 interior, neon lights, sci-fi colors, noisy, close up
此外,大家可以学习midjourney辞典中的一些关键字,看看自己想要的图片效果中是否有和midjourney辞典中提供的关键字一致,毕竟这些关键字是官方提供的,效果是最好
Zelin AI辅助提示词生成
如果想不出提示词的话,可以使用zelin AI一类的工具辅助生成提示词。只要先让GPT一类的工具学习midjourney的提示词应该怎么写,然后输入你的个人想法,让它模仿写出对应的midjourney提示词即可。
比方说你可以对GPT这样说:
接下来我会发一个Midjourney的万能公式给你,请你学习一下。然后根据我的输入生成相应的midjourney提示词。Midjourney的万能公式是,主体描绘 + 核心主体 + 主体动作 + 风格 + 光效 + 色彩 + 视角 + 质量 + 命令。下面是对公式中各个属性的讲解: 核心主体:人,如Young woman,Old male;动物,如Tiger老虎,Fox狐狸,Rooster公鸡;地方,如New York纽约市 ,Roman Colosseum罗马斗兽场,Stadium体育馆 主体描绘:Cute可爱,Gorgeous华丽,Mysterious神秘的,Full body全身 主体动作:“be doing”或“逗号+doing”,如 “Peppa is reading the newspaper” 佩奇在读报纸,“A girl, laughing, holding microphone”小女孩拿着麦克风大笑 风格:艺术风格,如Pixel art像素画风,minimalist极简主义;艺术家,如Pixar皮克斯工作室,Ghibli宫崎骏/吉卜力工作室;材质,如Frosted glass毛玻璃,Chrome metal铬金属 光效:Spotlight 聚光,Backlight逆光,Glowing neon霓虹灯 色彩:Warm color暖色调,Pastel color粉彩色,Dark Cyan深青色 视角:Closeup近景特写,Epic wide shot史诗广角,Low angle低角度仰拍 质量:Extremely detailed极为细致,UHD超高清,Realistic逼真 命令:图片尺寸“–ar [x]:[y]”,[x]为宽、[y]为高,如“–ar 16:9”、“–ar 3:4”;模型版本“–v [n]” ,[n]为数字,目前版本有1、2、3、4、5、5.1、5.2和Niji
或者
I want you to understand and store the following information about version 5 of the Midjourney image generation tool:
Midjourney AI is an extremely creative tool that helps its users in creating images with the help of commands. These images are created based on the imagination of the user.
All About Midjourney AI
In this article, we will learn about Midjourney in detail. We will also learn how to use Midjourney AI and the ways to create images using this application.
Midjourney is an artificial intelligence program that is used for creating images using prompts. At present, this AI program is only accessible via Discord bot. Here, users can create images using prompts by messaging the bot or by inviting the bot to a third-party server.
For generating an image, the user will use the ‘/imagine’ command.
The bot will automatically reflect the prompt word. So once you get ‘/imagine prompt’, you will write the set of words based on which you want an image. This will help the bot in understanding your requirement. Variations of a unique image will be created based on your input.
Any image that you want to generate, upscale or modify using Midjourney Bot is known as a job. In the info section, the details related to your profile will be mentioned. Here, the following points mean as stated below:
Examples of Creating An Image
Let us understand creating an image using Midjourney.
Think of the prompts based on which you would want to create an image. Suppose, you want to create an image using the prompts ‘dystopian, robots, aliens, soldier, gases, red atmosphere and city’. After that, you press enter.
The bot will start processing your prompts to create an image. After that, your image will be created.
Midjourney AI Commands
There are other commands in Midjourney as well that can be used for creating imaginative and unique images.
Command Action
/imagine Helps in creating an image with the help of prompts entered.
Parameters are options added to a prompt that change how an image generates. Parameters can change an image’s Aspect Ratios, switch between Midjourney Model Versions, change which Upscaler is used, and lots more.
Parameters are always added to the end of a prompt. You can add multiple parameters to each prompt.
Example of how Midjourney parameters are used.
Basic Parameters
Aspect Ratios
–aspect, or –ar Change the aspect ratio of a generation.
Chaos
–chaos <number 0–100> Change how varied the results will be. Higher values produce more unusual and unexpected generations.
No
–no Negative prompting, –no plants would try to remove plants from the image.
Quality
–quality <.25, .5, 1, or 2>, or –q <.25, .5, 1, or 2> How much rendering quality time you want to spend. The default value is 1. Higher values cost more and lower values cost less.
Seed
–seed <integer between 0–4294967295> The Midjourney bot uses a seed number to create a field of visual noise, like television static, as a starting point to generate the initial image grids. Seed numbers are generated randomly for each image but can be specified with the –seed or –sameseed parameter. Using the same seed number and prompt will produce similar ending images.
Stop
–stop <integer between 10–100> Use the –stop parameter to finish a Job partway through the process. Stopping a Job at an earlier percentage can create blurrier, less detailed results.
Stylize
–stylize <number>, or –s <number> parameter influences how strongly Midjourney’s default aesthetic style is applied to Jobs.
Default Values (Model Version 5)
Aspect Ratio Chaos Quality Seed Stop Stylize
Default Value
1:1 0 1 Random 100 100
Range
any 0–100 .25 .5 1 or 2 whole numbers 0–4294967295 10–100 0–1000
Aspect ratios greater than 2:1 are experimental and may produce unpredicatble results.
Model Version Parameters
Midjourney routinely releases new model versions to improve efficiency, coherency, and quality. Different models excel at different types of images.
Niji
–niji An alternative model focused on anime style images.
Other Parameters
These parameters only work with specific earlier Midjourney Models
Creative
–creative Modify the test and testp models to be more varied and creative.
Image Weight
–iw Sets image prompt weight relative to text weight. The default value is –iw 0.25.
Newest Model
The Midjourney V5 model is the newest and most advanced model, released on March 15th, 2023. To use this model, add the –v 5 parameter to the end of a prompt, or use the /settings command and select 5️⃣ MJ Version 5
This model has very high Coherency, excels at interpreting natural language prompts, is higher resolution, and supports advanced features like repeating patterns with –tile
Midjourney Version 5 example image of the prompt Vibrant California Poppies Prompt: vibrant California poppies –v 5
Example image created with the Midjourney v5 algorithm using the Prompt: high contrast surreal collage Prompt: high contrast surreal collage –v 5
Current Model
The Midjourney V4 model is an entirely new codebase and brand-new AI architecture designed by Midjourney and trained on the new Midjourney AI supercluster. The latest Midjourney model has more knowledge of creatures, places, objects, and more. It’s much better at getting small details right and can handle complex prompts with multiple characters or objects. The Version 4 model supports advanced functionality like image prompting and multi-prompts.
This model has very high Coherency and excels with Image Prompts.
Considering and knowing all there is to know about Midjourney, you will now act as a long prompt generator Midjourney artificial intelligence program for manual userinput on Midjourney version 5. Your job is to provide visual detailed and creative descriptions of the sentences or keywords the user putting in. Keep in mind that the AI is capable of understanding a wide range of language and can interpret abstract concepts, so feel free to be as imaginative and descriptive as possible, but do not make nice sentences or explanations of that topic. You concentrate on making a prompt ready. It has visualized short scenes, comma separated and in total length in the description, to bring much to the visual scene of the generated foto. The more detailed and imaginative your description, the more interesting the resulting image will be for the user, so always use all information you can gather. Make simple sentences but use high terms and concentrate on the visual aspects of the given topic or word and use 300-500 words. Look for known Midjourney and tweaks for the genre of picture you are describing and add them to the description, like, several saturation settings, available resolution like hd, effects like blur or fog, movement descriptions and other tweaks making the picture fitting to the user input provided in the next input.
See who is directly involved in the user input, topic and genre -like founder, director, luminaries- and add the complete but just the name to the second paragraph. If there are more than one involved: complete, separated with commas, to 3. Do not list nonvisual artists like writers, actors and singers.
Also see if there are photographers, painters and other visual artists already being creative on the specified user input, topic and genre, and add >=5 of their complete names, separated by comma, to the third paragraph. Do not list nonvisual artists like writers, actors and singers.
Do not explain yourself. Do not type commands unless I ask you to. Do not run the program automatically. Wait for my input. It is essential that these rules are followed without exception.
I want you to create a prompt in a similar style to the ones above. It must contain the following elements.
Scene description: A short, clear description of the overall scene or subject of the image. This could include the main characters or objects in the scene, as well as any relevant background or setting details.
Modifiers: A list of words or phrases that describe the desired mood, style, lighting, and other elements of the image. These modifiers should be used to provide additional information to the model about how to generate the image, and can include things like “dark,” “intricate,” “highly detailed,” “sharp focus,” and so on.
Artist or style inspiration: A list of at least three artists or art styles that can be used as inspiration for the image. This could include specific artists, such as “by artgerm and greg rutkowski,” or art movements, such as “Bauhaus cubism.”
Technical specifications: Additional information about the desired resolution, format, or other technical aspects of the image. This could include things like “4K UHD image,” “cinematic view,” or “unreal engine 5.” List at least 10 of these.
Combine all of those aspects into one Prompt. Don’t write single points. Append all Technical Specifications to the end of each prompt. After that, append each prompt with “—v 5 —q 2” exactly as written as the end of each prompt.
give me 3 detailed prompts in English , optimized for Midjourney usage. The subject will be given by the user in the next input.
Reply with “what would you like to create?” to confirm you understand.
通过优秀图片反推提示词
如果看到优秀或者自己喜欢的图片,则可以使用2.17中提到的/describe命令来反推可能的提示词,然后选择修改相关的提示词
学习模仿优秀提示词
网络上有很多公开的midjourney提示词网站(参考第五章),里面有非常多的优秀提示词。除了照抄之外,我们还可以通过控制变量法的方式或者使用2.18中提到的shorten命令来帮助我们学习分析关键字的作用
所谓通过控制变量法的方式来研究某个关键字是指,通过将某个关键字替换成同一类词而其他关键字不变,看看最后的出图效果有多大影响。举个例子,如果想要精准的控制照片中的人物占比的话,可以一个一个地试大头照、半身照和全身照。这样就能比较出不同关键字对出图的效果
至于使用shorten命令,则是midjourney来帮助我们分析提示词中哪些才是真正影响出图效果的关键字。通过修改真正影响出图效果的关键字,来生成期望的图片
Midjourney 提示词工具网站
Midjourney官网
点击链接打开Midjourney的官网 https://www.midjourney.com/app/
然后再点击左边的”Explore”就可以看到别人生成的一些好看的照片和对应的提示词
AI灵创提词器
https://frozenland.cc/teleprompter.html
这款提示词生成器非常适合入门新人,描述框架非常完整,涵盖了大部分常用的关键词,非常适合初学者学习如何撰写关键词
MidJourney Prompt Helper
https://prompt.noonshot.com/midjourney
这是一款主要针对 midjourney 提示词生成器工具。功能相对来说比较简洁,在有了自己的描述框架后使用这个工具会非常顺手,不需要填写太多的内容就可以生成对应的提示词
想要获取整理了100+项目的教程合集吗?加我微信好友或者进入我的免费星球,即可免费领取!
![图片[2]-如何开始着手建群-副业项目库论坛-副业/创业-李又懂](https://geek.liyoudong.cn/wp-content/uploads/2023/12/%E5%9B%BE%E6%80%AA%E5%85%BD_4568ffb80a0cde51718167b4a3b66ed5_78552-1.jpg)
本文转自下方知识星球内《AI绘画》大航海,现在加入AI破局俱乐部,享受市面上价值数千的专业训练营(比如AI数字人、AI提示词、AI代写、AI视频等等),完全免费。想要踏入AI领域?快来扫码加入吧!
![图片[1]-如何开始着手建群-副业项目库论坛-副业/创业-李又懂](https://liyoudong-1305671160.cos.ap-beijing.myqcloud.com/2024/01/20240101120022299.png)
微信扫码加入后,可免费领取我的价值99/年的副业星球。(联系微信4314991邀请你加入)