1、SD 界面的认识
我们安装了SD 之后,启动SD的界面,展开对其功能的初步探索。
通过以下这个截图,我将逐一为大家介绍SD界面中最常用的功能。
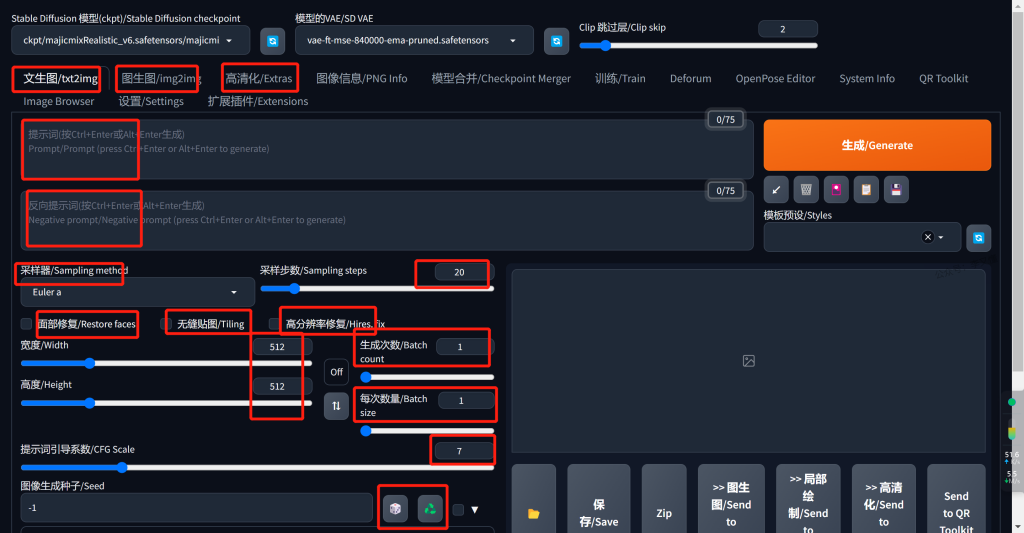
- 文生图:通过输入文字指令,让AI生成图片。(好比你向乙方阐述需求:“我想要一幅五彩斑斓的黑。”)
- 图生图:在已有文字指令的基础上,通过提供一张参考图片,让AI更好地理解你的需求。(就好比乙方反复尝试却仍无法生成你期望的作品,此时你可以给他一张参考图片说:“我希望获得类似这幅图的效果。”)
- 高清化:通过AI技术,提升输入图片的分辨率,使其品质更加清晰。
- 正向提示词:描述你希望图片中出现的元素。(例如:“一个女孩”)
- 反向提示词:描述你不希望图片中出现的元素。(例如:“丑陋的”)
- 采样器:指AI绘画时所采用的不同算法。日常使用中,我们常用四五种,推荐使用带+号的几种。
- 采样步数:AI在处理图像时,需要进行一系列的加噪和去噪过程。采样步数表示AI模拟迭代去噪的次数。理论上,步数越多,图像越清晰。然而当步数超过20后,变化幅度较小,而耗时较长。一般默认为20步,20-30步的取值范围已经足够。
- 面部修复:针对含有人脸的图片,启用该选项即可实现类似拍照时的智能美颜效果。
- 无缝贴图:用以生成覆盖整个屏幕的纹理图片。除非有特殊需求,否则不要随意勾选。
- 高清修复:在设定较低宽高的图片输出后,加入高清修复选项可以进一步优化画质。本质上相当于再次进行图生图操作。
- 宽和高:分辨率调整。一般建议设置在1000左右,不宜过高或过低。根据图片比例可调整至如800×800的正方形尺寸。
- 生成次数和每次数量:由于AI出图具有一定的不稳定性,需要多次尝试以达成满意效果。生成次数即每批次生成的图片张数,每次数量则为生成多少批次。若生成次数设置过大,可能出现显存不足的情况。
- 提升词引导次数:该数值越高,AI生成的图片将越忠实于你的提醒词。一般7-12为较为安全的取值范围。数值过大或过小均可能导致出图效果异常。
- 随机种子:点击骰子图标,表示随机生成图片。点击绿色循环箭头,则依据上一张生成的图片为基础继续创作。
在sd里面,我们可以把自己想象成一个画家
我们要确定画什么风格的画,是二次元的漫画,还是真实的人像

然后还要想想我们要画什么东西,是画人还是画动物

在sd里面,我们就是通过调整各种参数,去实现这个画画的流程
我把SD的基础使用流程分成了三步
1.选大模型
2.写关键词
3.参数设置
接下来我们就以这个流程,看看在sd里,怎么生成这样一张图片

2、SD 出图闭环
1.选大模型@吴东子
用 SD 作图,首先我们要选择合适的大模型checkpoint。
根据AI学习的图片的不同类型,SD中的大模型目前也大致分为三种:真实系、二次元、2.5D(介于真实和二次元之间,类似于3D动漫效果)。
不同的大模型,就代表着不同的照片风格
现在我们要画的是一个二次元的小姐姐,那就在左上角这里选一个二次元的大模型
在网盘里面,我给大家准备了一些比较好用的大模型,大家可以根据文件夹的名字下载对应的模型
这些模型需要下载放到一个固定的文件夹里面
在SD的文件夹里,也就是我们打开“A启动器”的那个文件夹
找到models文件夹,把大模型放到models文件夹里的Stable-diffusion文件夹就可以了
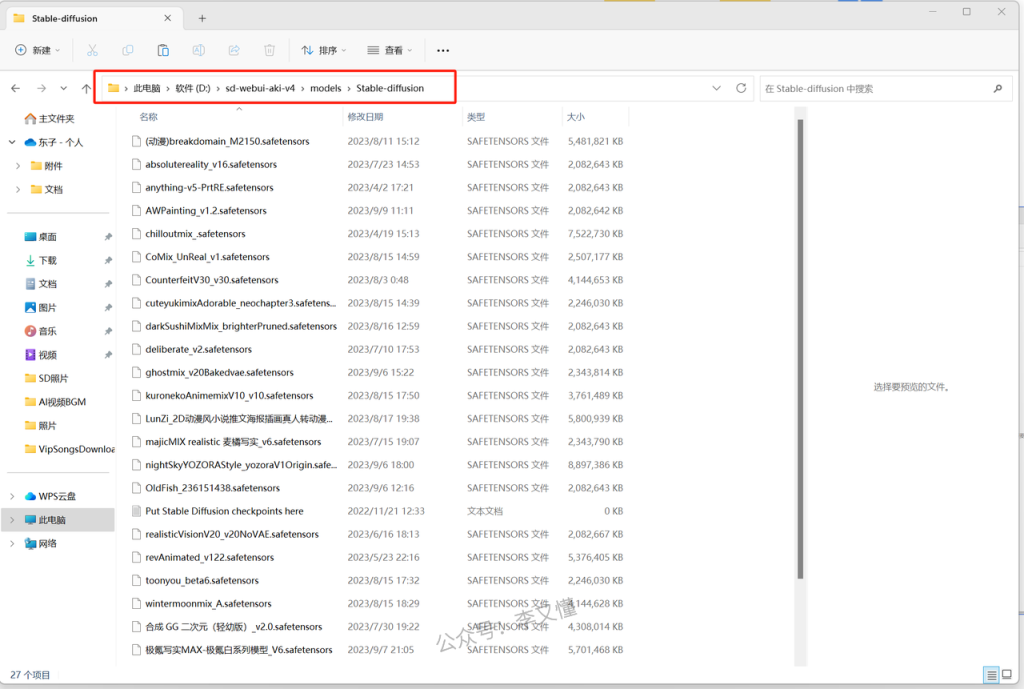
接着我们回到SD,点击旁边这个刷新按钮,这样新安装的大模型就会自动加载上来,我们就可以直接选用了
2.写关键词
选好大模型之后,我们就要想想画上面有什么东西
过一些单词或短语,将画面形容出来告诉SD,那我们写的这些词语就叫关键词
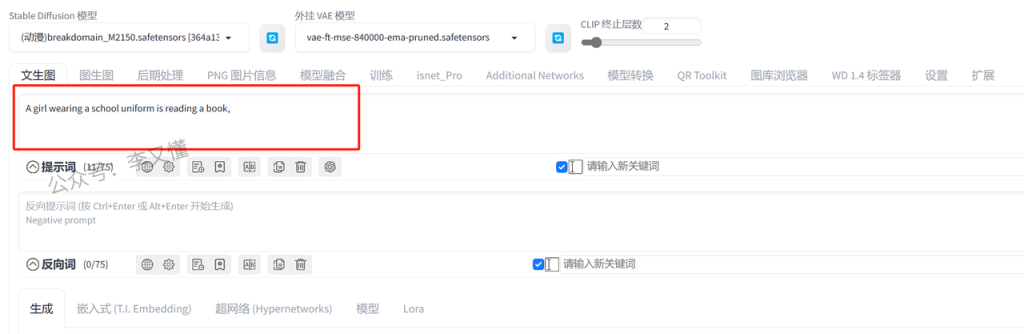
比如说,现在要生成“一个穿着校服的美女在看书”的照片,那这个句子就是我们的关键词
在翻译软件把这句话翻译成英文

把英文关键词复制到SD里面,这样我们的关键词就写完了
为了让照片出来的效果更好,我们还会加上负面关键词
也就是我们不希望画面会出现的东西,比如低质量、多手或者多脚这些
负向关键词一般情况下都是通用的,不用每一次都重写
这里我已经给大家准备好了一段通用的负面关键词,直接复制就行
你如果还有什么不想出现在照片上的东西,也可以自己加上去
通用的负面关键词:
EasyNegative, ng_deepnegative_v1_75t, badhandv4,(worst quality:2), (low quality:2), (normal quality:2), lowres, ((monochrome)), ((grayscale)), bad anatomy,DeepNegative, skin spots, acnes, skin blemishes,(fat:1.2),facing away, looking away,tilted head, lowres,bad anatomy,bad hands, missing fingers,extra digit, fewer digits,bad feet,poorly drawn hands,poorly drawn face,mutation,deformed,extra fingers,extra limbs,extra arms,extra legs,malformed limbs,fused fingers,too many fingers,long neck,cross-eyed,mutated hands,polar lowres,bad body,bad proportions,gross proportions,missing arms,missing legs,extra digit, extra arms, extra leg, extra foot,teethcroppe,signature, watermark, username,blurry,cropped,jpeg artifacts,text,error
到这里我们的关键词就全部写完了
3.参数设置
接下来就是一些参数的设置,用来调整图片的细节和整张图片的大小
如果你没有很了解这些参数代表什么也没关系,直接照抄就行了
01.迭代步数
首先是迭代步数,意思就是我们要在这幅画上面画多少笔
画的越多,画面就越多细节
但不是说步数越多越好,电脑配置比较低的电脑可能会带不动,导致照片无法生成
所以,电脑配置稍微低一点的,就设置在20~25步
电脑配置比较好的,就可以设置在25~30步之间
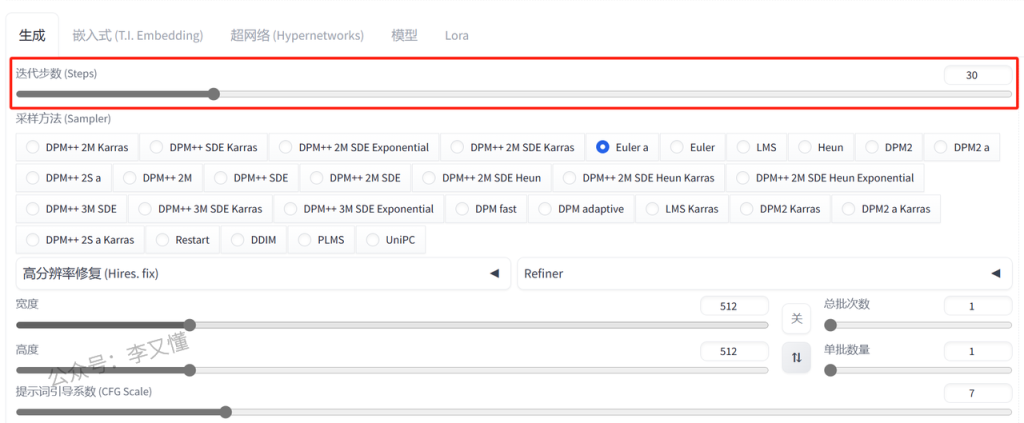
02.采样方法
不同的采用方法,就相当于我们画的每一笔的方式不一样
最后会导致生成出来的图片有所差别
框出来的这几个采样方法,出图速度比较快,而且出来的照片质量也比较高
采样方法有很多,但是大部分都不会用到,这里我也给大家测试过了,

03.宽度和高度
宽度和高度是用来调整照片的尺寸的
想要生成正方形或者长方形的照片,就可以通过调整宽度和高度的数值来实现
另外,宽度和高度的数值还会影响照片的清晰度
比如512*512 和 1024*1024,出来的都是1:1尺寸的正方形照片
1024的出图时间会更长,但是照片会更加清晰

这里的参数设置在一千左右,可以根据自己的电脑配置上下调整

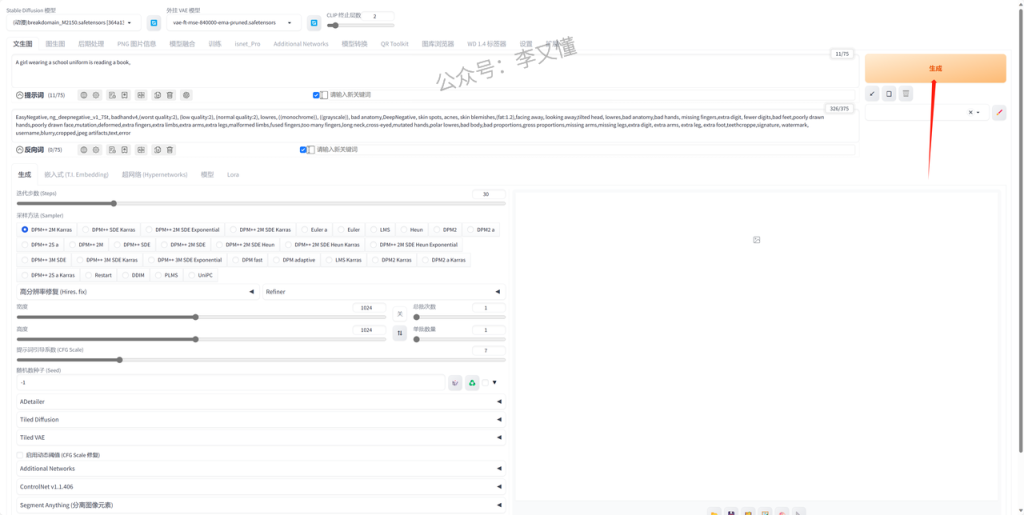
4.生成照片
所有参数设置好了之后,就可以点击右上角的“生成”按钮
稍微等一下,照片就出来了
如果对照片不满意的话,就继续点“生成”,这个操作就叫抽卡
每一次都会生成出来不一样的照片
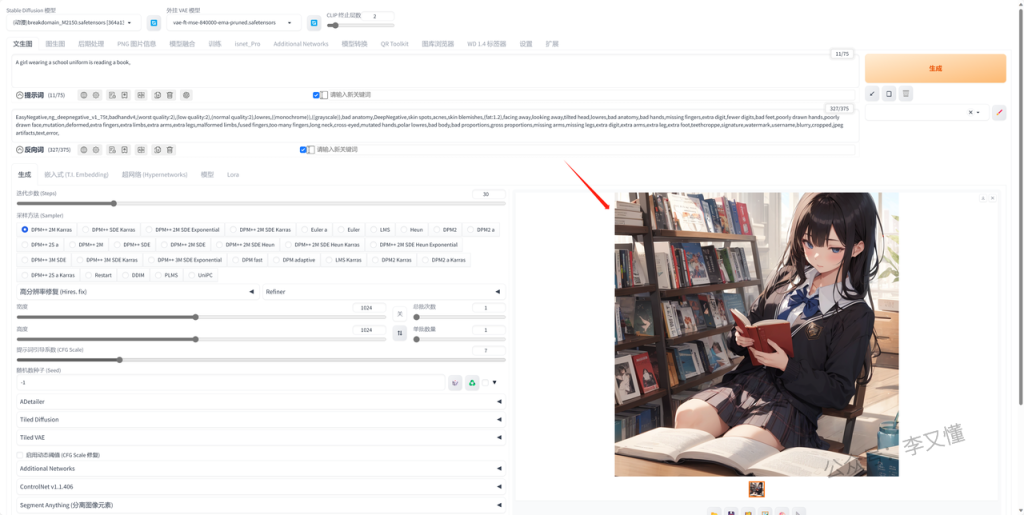
如果觉得照片不错,就可以把图片下载下来

3、其他功能
到这里你就已经掌握了SD的基础用法,并且已经生成出来了一张还不错的照片
接下来我们课程的其他所有操作都是为了让生成出来的这张照片变得质量更高,更加符合我们脑海里的画面
一)提示词
1、什么是提示词prompt?
提示词不仅仅在AI绘画中非常重要,而是在目前所有的AI工具中都不可替代。我们可以看到网络上一个顶级的训练AI的提示词工程师的薪资高达几十万或者更多。
提示词(prompt)是用于激发或引导AI生成特定内容的关键词或短语。
提示词是对AI输入的简短指示,向AI系统的表达自己的预期输出内容或风格,有效地告诉AI你希望看到的内容,使AI能够更准确地满足你的需求。
简单来说,就是我们作为甲方,Ai作为乙方,我们对AI提的要求——我要画什么?。
比如:一个美女。就是一个最简单的提示词。
2、什么是好的提示词?
我们作为甲方,都会向乙方提要求,但是最后的结果却相差很远。这就是因为,并不是所有的要求都是好的提示词。
一个美女。这是一个prompt。
一个美女,骑着摩托,在道路上。也是一个prompt。
一个美女,骑着摩托,身穿紧身衣,带着头盔,在道路上。也是一个prompt。
可想而知,这三个prompt由AI做图,出现的结果是完全不同的。
对SD而言,提示词分为两个部分。如图:
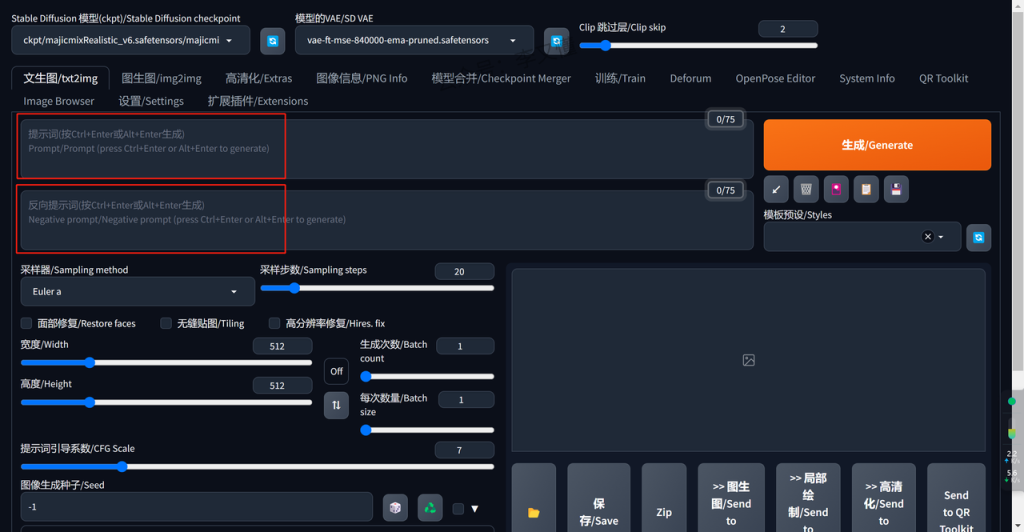
一个是正面提示词,即你想要图片里出现什么元素。
一个是负面提示词,即你不想要图片里出现什么元素。
先说正面提示词,当我们的提示词写的越准确,AI做出的图就越接近我们的脑海中的想象。
prompt可以是单词(一个女孩、漂亮、站着、森林)、一个词组(一个漂亮女孩、站在森林里)、或者一个句子(一个漂亮的女孩子站在森林里)。
需要注意的是:SD目前只能看懂英文,英文好的小伙伴可以直接在提示词部分输入英文,英文不好的小伙伴也不要担心,直接用翻译器翻译一下就好了。
当我们把提示词输入完毕,点击右边的生成按钮,我们的图片马上就生成了。

这个图片是不是很简略,那是因为我们的提示词还不够详细。
一个漂亮女孩站在森林里。女孩是什么样子的,穿着什么衣服,带着什么首饰,森林里有什么?这些Ai都不知道,出来的图自然是很随机的。所以我们也把出图形象的叫做抽卡。
当我们的提示词越详细精确,抽到好卡的概率就越大。
一个好的图片的提示词可能有几百个单词,虽然prompt不一定越多越好,但是多些一点描述词多数时候比少一点要好。
一般来说,词组是AI绘画提示词比较好的模式,并不很依赖语法和句子。词组直接记得使用一个英文中的逗号,换行也要记得打一个英文逗号。
一个好的正向提示词应当具备这几个方面的内容:
1、内容型提示词
人物和主体特征:服饰穿戴、发型发色、五官特点、面部表情、肢体工作。
场景特点:室内还是室外,大的场景(森林、城市、街道)、小的细节(白色的花、绿色的树)
环境光照:白天还是黑夜、或者其他特定的时间段、阴天还是晴天、柔和的光线还是阴暗的光线、天空等
视角:距离远近、人物比例、观察视角、镜头的类型
2、标准化提示词
画质提示词:画质高还是低、分辨率高或低
画风提示词:插画、二次元、写实系、或者其他的画家风格
根据上面的详细提示,我们写出下面的提示词:
(1girl:1.6), solo,nilou,genshin impact , solo, long hair, jewelry, blue gemstone, earrings,horns, crown, cyan satin strapless dress, white veil, neck ring, red hair, igreen eyes,
indoor, room, house, sofa, wooden floor, plant, flowers, trees, windows,
day, morning, sunlight, dappled sunlight, backlight, light rays, cloudy sky,
full body, wide angle shot, depth of field,
light particles, fantasy, wind blow, maple leaf, dusty,
masterpiecel, fbest qualityl fhighres, original, reflection, unreal engine, body shadow,artstationextremely detailed CG unity 8k wallpaper,
(illustration),(painting), (sketch), anime coloring, fantasy,
exaggerated body proportions, greasy skin, realistic and delicate facial features, SFW,
点击生成,等待奇迹:

这幅图片是不是还不错。
现在我们继续说负面提示词:
当我们出了几次图之后,就会发现AI有时候会生成很多多余的东西,比如:多了几根手指,多了几条大腿,或者还有一些丑陋的、克苏鲁的内容。
这就要通过负面提示词去避免这些情况。
通过负面提示词,告诉Ai,我不要这些内容。
比如:低质量的、丑陋的脸、多余的手等等。
下面送给小白一套几乎通用的负面提示词(可以直接抄)
NSFW, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),
除了这些内容,还有什么不想在图里看到的,都可以写到负面提示词里面。
3、权重
在上面分享给大家的正面或者负面提示词中间,我们可以看到很多括号还有冒号以及数字。
这些是什么作用呢?
举个例子:我在提示词中写了red hair,但生成的图片有可能是黑色的头发或者黄色的头发。
因为提示词写的太多,AI很多时候不能全部识别到。我需要让Ai注意到这个词组。
方法就是给这个词组增加权重。
同时有时候,我们也需要让一些图片里的内容不那么重要,我们也需要减少权重。
改变权重有两种方法:
1、直接用括号()把词组圈起来,然后加上冒号:,最后填入数字。
比如:(red hair:1.6)
这就是把red hair这个词组的权重增加了1.6倍。
大于一就是增加权重,小于一就是减少权重。
2、用不同的括号。
()是1.1倍。可以套娃,(()),每套一层增加1.1倍。
【】是0.9倍。相当于减弱权重。也是可以套娃,【【】】,额外✖0.9倍。
{}则是每层额外1.05倍。
你可以根据自己的需要,增加或者减少权重。
但根据实际操作,一般保证权重在1±0.5左右效果最好。一般一个词权重大于2就会容易出现异常的画面。
二)Lora
1、Lora 有什么用?
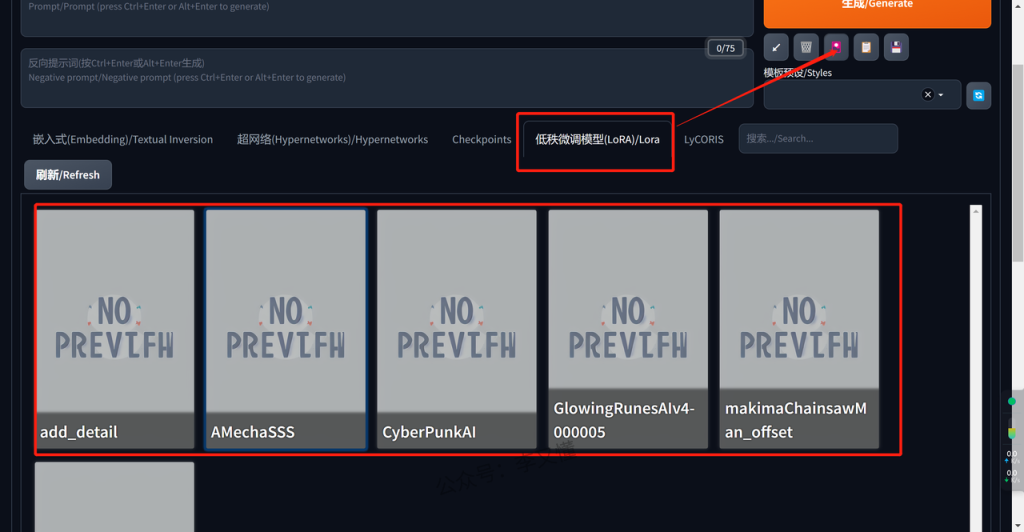
当你点击生成按钮下方的红色图标,就会出现上图中的内容,红框里的就是微调模型Lora。
我们通常也称之为微调模型,用于满足一种特定的风格,或指定的人物特征属性。
如果说大模型是关乎一个房屋的主梁,那么Lora就是主梁上的雕刻,让主梁更加细节。
我们作为魔法师开心的学习了咒语,复制到自己的SD中,同时选择了相同的大模型,但是跑出的图片仍然有很多细节方面不同,大概率就是用了不同的Lora。
这就导致了学习的咒语是一个开着机甲的少女,复制出来是一个骑着摩托的少女。可能就是缺少了一个机甲的Lora。没有Lora,就让自己的作品成了高仿,虽然比赝品要好一些,但离真品还是有很大距离。
很多大模型都有适配的Lora,我们可以一起下载使用,也可以根据自己对于Lora的理解叠加使用。效果也会很不错。
2、Lora的使用
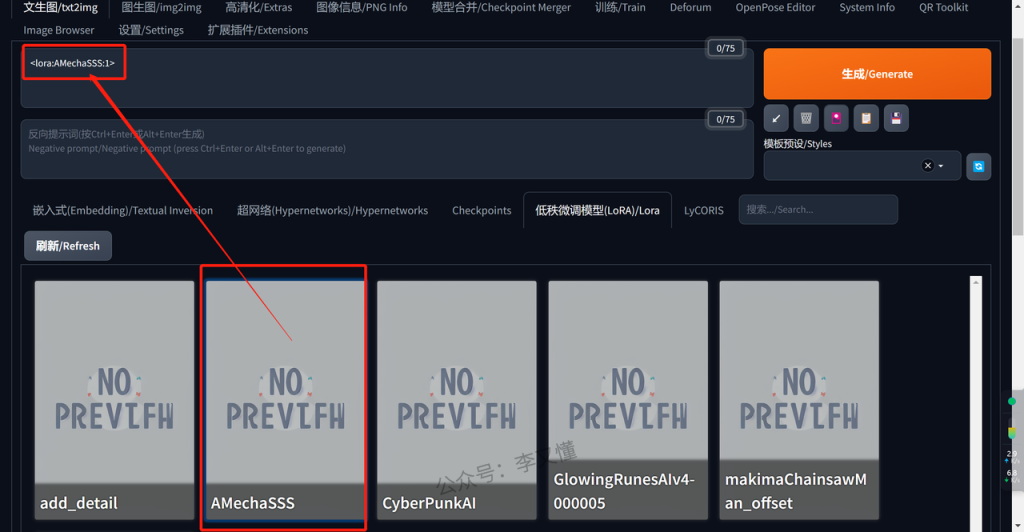
(如下图):
点击 lora 调用按钮后,在tag栏就可以看到一个词条,然后再继续编辑描述语即可。
直接点击我们要用的Lora,关键词的文本框里面就会自动添加一串英文前。
半部分是这个lora的名字,后面的数字1是权重。
lora的权重一般设置在0~1之间,因为权重大于1,出来的照片可能会变得奇奇怪怪。
只是要注意,和关键词一样,lora之间也要用英文状态下的逗号分隔开
三)图生图
1、什么是图生图?
在文生图的内容里,我们借助于提示词prompt让AI明白我们想要画什么。
但AI的图片生成是有着很大的随机性的。生成的图片未必符合你的要求,就如同甲方客户和乙方设计师之间的矛盾一样,很难调解。
这时候,如果有一个参考图,设计师就能更加清楚甲方的要求。
AI绘画也是一样,当提示词不足以让AI完全理解我们的要求,我们也可以给AI一张图片作为参考,让AI更能理解我们的想法。
这就是图生图的意义。
2、图生图的流程
1、导入图片:可以直接把图片使用鼠标拖进来,也可以点击上传然后进行选择。
2、写入提示词
和文生图一样,图生图也是需要提示词的。
虽然有了图片作为参考,我们可以简单使用一个词组,比如:1girl。但这样生成的图片多半不能如你所愿。
想要生成更满足自己想法的图片,肯定需要提示词更精确。
3、调整参数
图生图的参数基本和文生图的参数数值设置一样。
比如:采样器、采样步数等。
需要我们关注的是重绘幅度这个参数,重绘幅度顾名思义是把图片改变的幅度,不过一般过小过大都不合适,一般适合在0.6-0.8之间,可以多尝试几次选择合适自己的数值。
同时要注意一个参数是宽和高,最好和原图一致,避免画面拉伸变形。我们可以根据原始图片设置宽高比。
如果原图的比例太高,我们可以同比例缩小。比如一张3000✖3000的图片,我们可以直接把宽和高设置为800✖800。
3、种子的应用
虽然图生图让Ai生成的图片更加容易控制。但依然存在着一定的随机性。
比如:背景的变化,细节的变化。
假如一个图片,我们喜欢生成的细节,但不喜欢背景。那么我们就可以使用种子去约束图片的生成。
我们每生成一个图片,都会生成一个随机种子。我们使用同一个种子就可以生成相似度更高的图片。
点击循环按钮,我们就使用上一张细节好的图片的种子作为出图的参照。
或者点击我们其他需要的图片,在下面的数值中找到seed后面的一串数字,就是这张图的种子。
然后通过相同种子,再加上一些提示词的约束,生成我们想要的图片。
4、图生图应用
通过上面的流程,我们基本掌握的图生图。
当我们需要把一个游戏里的人物转换成真人时,完全可以把游戏里的人物图片先上传给Ai,然后加入一个真实系的模型,通过提示词的约束,就可以得到一个游戏里人物的真人模型了。
这样我们就可以把二次元的爱豆搬进现实中了。
我们也可以把一些物品、风景等,通过真人模型拟人化。
除了上面的图片,我们也可以把涂鸦的作品做新的生成等等。各种好玩的方法就等我们去发掘。
四)局部重绘
局部重绘可以改变你想让图片改变的地方,可以用来换装、换脸、换背景等等。有蒙版,但是不同于涂鸦绘制,不能选择颜色,只能涂黑,但是我们可以使用提示词对重绘的内容进行控制。
参数介绍
1、蒙版模糊度
主要控制蒙版和非蒙版之间的边缘过渡,数值小的话,过渡起来比较突几,数值大的话就就会比较自然数值最大的时候蒙版就透明了
2、蒙版模式
控制你需要重绘的区域
绘制蒙版内容:只改变蒙版区域,其他地方不变
绘制非蒙版区域:改变没有蒙版的区域,保留蒙版的区域保持不变
3、蒙版蒙住的内容
填充:原图的内容不作为任何参考。(生成的图比较随机,不建议使用。)原图: 根据原图的内容生成。 (比较常用的功能。)潜在噪声:和填充一样,不参考原图内容,但细节比填充丰富无潜在空间: 和填充一样,不考虑原图内容,细节也会更多些
4、重绘区域
融合度比较好,但蒙版区域细节有限全图:整张图片都需要处理,仅蒙版:集中处理蒙版区域,细节好,但整张图融合度低
5、仅蒙版绘制参考半径
对于蒙版和非蒙版的边缘元素参考数值越低,生成的图片随机性会越大。数值越高,更接近原图
6、涂鸦蒙版局部重绘
类似于涂鸦绘制,可以使用画笔,且可以使用多个颜色。参数介绍:相比于局部重绘,只多了一个蒙版透明度蒙版透明度数值越小,颜色越浅。数值越大,颜色越深
图生图中几种功能的对比
1、涂鸦:不能蒙版,画笔的颜色选择就是最终效果,颜色会比较突
2、局部重绘:只有蒙版,所有的重绘都是由提示词进行控制的。
3、涂鸦重绘:有蒙版,画笔决定最终颜色,但可以通过控制透明度控制深浅,而且可以用多个颜色。
想要获取整理了100+项目的教程合集吗?加我微信好友或者进入我的免费星球,即可免费领取!
![图片[2]-如何开始着手建群-副业项目库论坛-副业/创业-李又懂](https://geek.liyoudong.cn/wp-content/uploads/2023/12/%E5%9B%BE%E6%80%AA%E5%85%BD_4568ffb80a0cde51718167b4a3b66ed5_78552-1.jpg)
本文转自下方知识星球内《AI绘画》大航海,现在加入AI破局俱乐部,享受市面上价值数千的专业训练营(比如AI数字人、AI提示词、AI代写、AI视频等等),完全免费。想要踏入AI领域?快来扫码加入吧!
![图片[1]-如何开始着手建群-副业项目库论坛-副业/创业-李又懂](https://liyoudong-1305671160.cos.ap-beijing.myqcloud.com/2024/01/20240101120022299.png)
微信扫码加入后,可免费领取我的价值99/年的副业星球。(联系微信4314991邀请你加入)