目前对数字人领域探索比较多,之前看到微软推出了自己的数字人之后,在破局星球立刻发布了一条风向标,体验还是相当 Nice,文末会有展示视频。
微软的叫法是:文本转语音头像!这项创新功能不仅允许用户通过文本输入来创建能够说话的头像视频,还能使用人类图像训练来制作实时互动的智能机器人。
今天这篇文章中,我会详细介绍这个功能的特性、优势和技术细节,并通过一系列实例展示它在不同场合的应用方法。
1、什么是文本转语音头像?
文本转语音头像是一项结合了视觉技术的文本转语音功能,它可以让用户制作出 2D 逼真头像的合成说话视频(让图片开口讲话)。这些头像模型是通过深度神经网络训练而成的,训练材料来自于真人视频录制样本(声音克隆)。
头像的声音则是由先进的文本转语音声音模型所提供(TTS),使其更加生动真实。
微软说构建头像的主要有两个原因:
- 一是因为传统的视频内容制作不仅耗时而且成本高昂,涉及到搭建拍摄环境、录制和剪辑等多个环节。文本转语音头像使用户可以更高效、更简便地创建视频内容,只需输入文本,就能制作出培训视频、产品介绍、客户评价等。
- 二是随着 Azure OpenAI 服务及神经文本转语音技术的推出,数字互动变得更加自然和流畅。文本转语音头像让用户可以创造出更生动、更引人入胜的数字交互体验,例如可以利用头像开发对话型代理、虚拟助手、聊天机器人等。
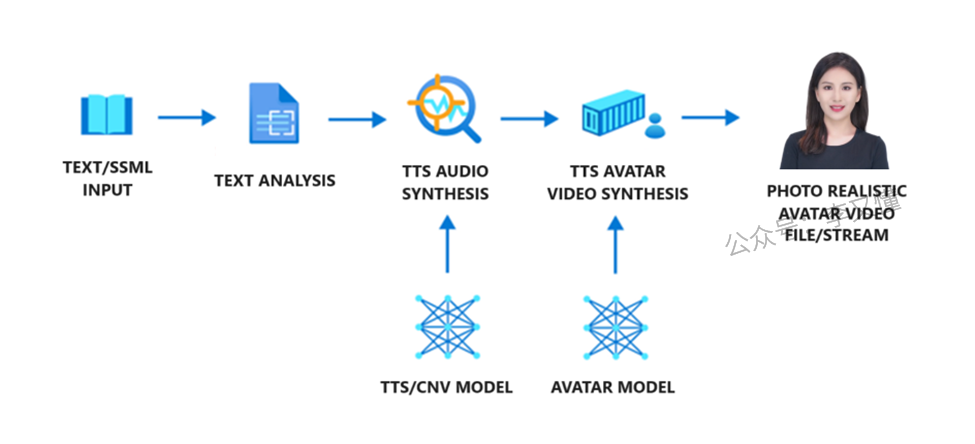
在头像内容生成的流程中,有三个核心环节:文本分析器、文本转语音音频合成器和文本转语音头像视频合成器。首先,文本被输入到文本分析器中,并被转化为音素序列。接着,文本转语音音频合成器根据文本的声学特征来预测并合成声音,这两个步骤都由文本转语音的声音模型完成。最后,神经文本转语音头像模型根据这些声学特征预测唇形同步的图像,从而生成逼真的合成视频。
2、这次发布包括哪些内容?
我们目前提供两种文本转语音头像功能:内制版和定制版。
2.1内制版文本转语音头像
微软在 Azure 平台上为订阅用户提供了预制的文本转语音头像产品,可以即插即用。这些头像能够根据文本输入用不同的语言和声音进行交流。客户可以从多种选项中选择一个头像,用来创造视频内容或开发具有实时头像反应的互动应用程序。

2.2定制版文本转语音头像(需要申请)
定制版功能使客户能够为他们的产品或品牌创建个性化头像。客户可以上传自己的头像视频录制,系统将利用这些视频训练一个定制头像的合成视频。客户可以为他们的头像选择预制或定制的神经语音(声音克隆)。如果同时使用同一人的声音和形象创建定制的神经语音和文本转语音头像,该头像将非常接近于该人。(数字人克隆)
作为微软对负责任 AI 的承诺,文本转语音头像功能旨在保护个人和社会的权利,促进透明的人机交互,并防止有害的深度伪造和误导性内容的传播。因此,定制头像是一个限制访问功能,仅限注册用户使用,并且只适用于特定用例。要在你的商业应用中使用此功能,请在此处注册你的应用案例并申请访问权限。
3、文本转语音头像可以做什么?
使用文本转语音头像,无论是利用预制头像还是定制头像,你都可以创造出各种引人入胜的视频,如培训视频、演示视频等。
它还可以帮助你为客户、员工和其他受众提供富有互动性的应用程序体验。
Azure AI 语音宣布了文本转语音头像的公开预览,其中涵盖了多种应用场景,例如:
3.1批量视频内容创作
- 企业培训视频
- 产品介绍或广告材料
- 让 CEO 的数字分身在会议中发表演讲
3.2实时互动应用
- 旅游网站的聊天机器人
- 直播商业活动中的虚拟销售
- AI 老师在线授课,可答疑解惑
- 回答员工疑问的虚拟 HR
4、如何使用?
微软本次发布的版本,同时支持 AzureAI Speech Studio 的 UI 工具和 API 访问
4.1 Azure AI Speech Studio


https://speech.microsoft.com/portal
4.2会说话的虚拟形象
4.3注册 Azure 账户
但是不管界面还是 API 版本,都需要注册 Azure 账户。如果新用户可以享受 12 个月的免费服务。
https://azure.microsoft.com/zh-cn/free/ai-services/

- 创建新的语音资源

- 在填写新的资源名称之前,需要先点击 转到 Azure 门户以使用高级设置进行创建 一个语音服务。



- 语音服务创建完成,重新创建语音资源。


基础的信息全部配置完成,就可以体验语音头像了。
4.4内置形象
内置形象 Lisa,提供几种不同的姿势:休闲坐姿,优雅的坐姿,优雅的站姿,技术坐姿,技术站姿。

选择语言和语音

插入分隔

自定义插入手势

调整语速

预览视频&下载视频

但是,测试下来,这个预览中,最终的视频只能生成一句,文本太长就会失败。
所以,接下来我就测试 API 版本试试。
5、API 版本测试
5.1GitHub 链接
可直接使用 官方提供的 Notebook 来制作头像视频:https://github.com/Azure/gen-cv/tree/main/avatar/video


https://github.com/Azure/gen-cv/tree/main/avatar/video
5.2谷歌 Colab 链接
下面是我下载之后在谷歌 Colab 中修改后的版本:
https://colab.research.google.com/drive/1r-MmWYHqf53qHTbjVkfD73WwKn-QVlmD?usp=sharing

5.3运行代码及解释
下面写一下我跑这个代码过程中的详细步骤,遇到很多问题以及我是如何解决的。
代码框1
import requests
import json
import time
import os
from dotenv import load_dotenv这段代码是一个 Python 脚本的一部分,其中包含了一些模块导入语句。每个导入的模块都有其特定的用途:
import requests:requests是一个流行的 Python 库,用于发送 HTTP 请求。这意味着代码中可能会涉及到与网络资源的交互,如 API 调用、网页内容获取等。
2. import json:
json模块用于处理 JSON 数据。JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,常用于网络通信。这表明脚本可能会处理 JSON 格式的数据,如解析来自网络请求的响应或将数据转换为 JSON 格式发送。
3. import time:
time模块提供了与时间相关的函数。这可能用于处理时间相关的操作,如延迟(等待)、记录时间戳、测量代码执行时间等。
4. import os:
os模块提供了一系列与操作系统交互的功能,包括但不限于文件和目录的管理、环境变量的读取、执行操作系统命令等。这可能表明脚本需要与文件系统交互,或者需要读取操作系统层面的配置。
5. from dotenv import load_dotenv:
dotenv是一个用于管理环境变量的 Python 库。load_dotenv函数用于加载.env文件中的环境变量。.env文件通常用于存储配置信息,如数据库连接字符串、API 密钥等,以避免将这些敏感信息硬编码在代码中。
综合来看,这段代码可能是一个涉及网络请求、数据处理、时间操作和环境配置管理的应用程序或脚本的一部分。它表明开发者可能在处理网络数据,同时关注代码的安全性和配置的灵活性。

好家伙,第一段就开始报错,但是不慌,这是跑 Python 代码时最常见的问题。
解决办法:缺啥补啥,此环境缺少 dotenv 库,于是执行 pip 进行安装。
!pip install python-dotenv

出师继续不利,这个错误没遇到过,直接把错误丢给 GPT,这不一下就知道什么原因了。原来是 Python 包名的问题。

!pip install python-dotenv

成功解决,继续下一段代码。
代码框2
# if not load_dotenv('./.env-avatar-video'): raise Exception("env file not found")
os.environ["SPEECH_SERVICE_REGION"] = "your_service_region" #替换为你的资源区域
os.environ["SPEECH_SERVICE_API_KEY"] = "your_api_key" #替换为你的资源秘钥
service_region = os.getenv("SPEECH_SERVICE_REGION")
subscription_key = os.getenv("SPEECH_SERVICE_API_KEY")
# print(service_region,subscription_key)
url_base = f"https://{service_region}.customvoice.api.speech.microsoft.com/api"
project_folder = '/content/my-project'ifnot os.path.exists(project_folder):
os.makedirs(project_folder)
# project_folder = './my-project' # your project folder# # os.makedirs(project_folder, exist_ok=True)
texttype = 'ssml'# ssml or PlainText# texttype = 'Plaintext'
ssml_path = os.path.join(project_folder, '/content/ssml.txt') # if your avatar text input is in SSML format
plaintext_path = os.path.join(project_folder, '/content/plaintext.txt') # if your avatar text input is plaintext format原代码中是需要通过内置环境变量来获取变量,但因为 Colab 环境问题,直接获取环境变量有很多限制。

所以这边我直接在代码中设置环境变量,但请注意,这样做可能会暴露敏感信息。
例如:
os.environ["SPEECH_SERVICE_REGION"] = "your_service_region" #资源区域
os.environ["SPEECH_SERVICE_API_KEY"] = "your_api_key" #资源秘钥这里有两个 API 需要从前面的语音资源中获取。

代码框3
# Helper functions
def download_file(url, local_path):
"""
Download a file from a given URL to a local path. This function streams the file from the URL and writes it in chunks to the local
file system. This allows it to handle large files that might not fit in memory.
Parameters:
url (str): The URL of the file to download.
local_path (str): The local path where the file should be saved.
Returns:
str: The local path to the downloaded file.
"""
with requests.get(url, stream=True) as r:
r.raise_for_status()
# Extract filename from URL
filename = url.split("/")[-1].split("?")[0]
local_filename = os.path.join(local_path, filename)
with open(local_filename, 'wb') as f:
for chunk in r.iter_content(chunk_size=8192):
if chunk:
f.write(chunk)
return local_filename上面这段代码是写了一个函数,待会我们生成视频之后,下载视频用的,暂时不用管。
代码框4
# load speaking script
if texttype == 'ssml':
with open(ssml_path, 'r') as file:
content = file.read()
elif texttype == 'Plaintext':
with open(plaintext_path, 'r') as file:
content = file.read()
else:
print(f'Error: Texttype needs to be either "ssml" or "Plaintext". Got {texttype} instead.')
print(content)这段代码是选择给头像的文案的文本方式:简单的纯文本文件 plaintext或者 更高级的语音合成标记语言 SSML格式。
简单的纯文本格式

这个例子展示了你可以用 SSML 让你的头像用不同的语言讲话,并且如何添加效果。我们使用的是小辰的声音,它能用几种语言讲话。这里是多语言才华横溢的小辰用法语说话。我的声音很容易被识别。 我可以用 15 种不同的风格讲话。如果你想要一个喊叫的头像,对我来说没问题!或者怎么样,来点耳语对话?你可以在我的语言中插入一个暂停,使用一个断句标签。使用音素来正确发音特定的单词,如 OpenAI 的 DALLE 模型。没有音素,神经语音会错误地说 DALLE。调整说话速度,所以如果你想,我可以说得非常快,或者说得相当慢。随意调整音调以提高声音,或者相反,如果你更喜欢那样。最后,这是你如何降低音量,或者让我说话更大声。我们希望这些示例能帮助你定制你的头像的沟通,以获得更引人入胜的体验。玩得开心!
更高级的语音合成标记语言(SSML)格式(推荐使用)
那么问题来了,什么是 SSML 格式?(文章最后会有视频解释)
SSML(Speech Synthesis Markup Language)格式是一种基于 XML 的标记语言,专门用于控制和定制文本转语音(TTS)系统的输出。它允许用户精确地指定语音合成的各种方面,包括发音、音调、音量、语速、停顿等。通过 SSML,用户可以让合成语音更加自然、表情丰富,并能够适应特定的语境和应用需求。SSML 格式常用于开发高度个性化的语音应用,如虚拟助手、自动语音响应系统、有声读物等。

<speak xmlns=”http://www.w3.org/2001/10/synthesis” xmlns:mstts=”http://www.w3.org/2001/mstts” xmlns:emo=”http://www.w3.org/2009/10/emotionml” version=”1.0″ xml:lang=”en-US”> <voice name=”en-US-JennyMultilingualNeural”> This example shows what you can do with SSML to let your avatar speak in various languages and how to add effects. We are using the voice Jenny Multilangual which is able to speak in several languages. <lang xml:lang=”fr-FR”>Voici le talent linguistique Jenny parlant français. Ma voix est bien reconnaissable.</lang </voice <voice name=”en-US-JennyNeural”> I can speak in 15 different styles. <s / <mstts:express-as style=”shouting”>If you want a shouting Avatar, no problem for me!</mstts:express-as <s / <mstts:express-as style=”whispering”>Or what about some whispered dialog?</mstts:express-as You can insert a pause <break strength=”medium” / in my speech with a break tag. Use a phoneme to pronounce specific words correctly like OpenAI’s <phoneme alphabet=”ipa” ph=”ˈdɑli”>DALLE</phoneme model. Without the phoneme, the neural voice would say DALLE, which is not correct. Adjust the speaking speed <prosody rate=”+30.00%”>so I can talk really fast if that’s what you want</prosody<prosody rate=”-40.00%”> or talk quite slowly.</prosody <prosody pitch=”+10.00%”>Feel free to adjust the pitch for more highness of the sound.</prosody<prosody pitch=”-20.00%”> Or the opposite if you like that better.</prosody <prosody volume=”-80.00%”>Finally, here is how you reduce the volume.</prosody <prosody volume=”+40.00%”>Or make me speak louder.</prosody We hope that these examples help you to customize your avatar’s communication for more engaging experiences. <s / <mstts:express-as style=”friendly”>Have fun!</mstts:express-as <s / </voice </speak
上面英文版本是官方给的示例。使用 GPT 直接转换为中文版本的,切记要保持格式不变。

<speak xmlns=”http://www.w3.org/2001/10/synthesis” xmlns:mstts=”http://www.w3.org/2001/mstts” xmlns:emo=”http://www.w3.org/2009/10/emotionml” version=”1.0″ xml:lang=”en-US”> <voice name=”zh-CN-XiaochenNeural”> 这个例子展示了你可以用 SSML 让你的头像用不同的语言讲话,并且如何添加效果。 我们使用的是小辰的声音,它能用几种语言讲话。 <lang xml:lang=”fr-FR”>这里是多语言才华横溢的小辰用法语说话。我的声音很容易被识别。</lang> </voice> <voice name=”zh-CN-XiaochenNeural”> 我可以用 15 种不同的风格讲话。 <s /> <mstts:express-as style=”shouting”>如果你想要一个喊叫的头像,对我来说没问题!</mstts:express-as> <s /> <mstts:express-as style=”whispering”>或者怎么样,来点耳语对话?</mstts:express-as> 你可以在我的语言中插入一个暂停 <break strength=”medium” /> 使用一个断句标签。 使用音素来正确发音特定的单词,如 OpenAI 的 <phoneme alphabet=”ipa” ph=”ˈdɑli”>DALLE</phoneme> 模型。没有音素,神经语音会错误地说 DALLE。 调整说话速度 <prosody rate=”+30.00%”>所以如果你想,我可以说得非常快</prosody><prosody rate=”-40.00%”> 或者说得相当慢。</prosody> <prosody pitch=”+10.00%”>随意调整音调以提高声音。</prosody><prosody pitch=”-20.00%”> 或者相反,如果你更喜欢那样。</prosody> <prosody volume=”-80.00%”>最后,这是你如何降低音量。</prosody> <prosody volume=”+40.00%”>或者让我说话更大声。</prosody> 我们希望这些示例能帮助你定制你的头像的沟通,以获得更引人入胜的体验。 <s /> <mstts:express-as style=”friendly”>玩得开心!</mstts:express-as> <s /> </voice> </speak>
然后我们需要创建 2 个文件,分别把两种格式的内容写进去。

代码框5
# generate avatar video
payload = json.dumps({
"displayName": "my avatar",
"description": "Vision AI Solution Accelerator Demo",
"textType": texttype, # PlainText, ssml
"inputs": [
{
"text": content
}
],
"synthesisConfig": {
"voice": "zh-CN-XiaochenNeural", # set voice name for plain text; ignored for ssml
},
"properties": {
"talkingAvatarCharacter": "lisa", # custom avatar. pre-built avatar: lisa
"talkingAvatarStyle": "technical-standing", # supported lisa styles: casual-sitting, graceful-sitting, graceful-standing, technical-sitting, technical-standing
"videoFormat": "webm", # mp4 or webm, webm is required for transparent background
"videoCodec": "vp9", # hevc, h264 or vp9, vp9 is required for transparent background; default is hevc
"subtitleType": "soft_embedded",
"backgroundColor": "transparent",
},
})
session = requests.Session()
session.headers.update({
'Accept': 'application/json',
'Ocp-Apim-Subscription-Key': subscription_key,
'Content-Type': 'application/json'
})
url_com = f'{url_base}/texttospeech/3.1-preview1/batchsynthesis/talkingavatar'
response = session.post(url_com, data=payload)
print(f'Status code: {response.status_code}')
if response.status_code >= 400:
print('Job submission failed. Please verify your subscription key and try again.')
print(response.text)
else:
print('Job submitted successfully. Processing', end=' ')
r = response.json()
while True:
result = session.get(f'{url_base}/texttospeech/3.1-preview1/batchsynthesis/talkingavatar/{r["id"]}')
if result.json()['status'] == 'Succeeded':
print('\n\nReady. Synthesized video:\n' + result.json()['outputs']['result'])
break
if result.json()['status'] == 'Failed':
print('synthesis failed')
print(result.json()['properties']['error'])
break
print('.', end = '')
time.sleep(10)这里主要配置几个参数:
语言和音色:”voice”: “zh-CN-XiaochenNeural”, 从语音库中选择合适的,中文,晓辰。

选择头像形象:”talkingAvatarCharacter”: “lisa”, 内置的目前只有 Lisa。

选择姿势:”talkingAvatarStyle”: “technical-standing”,休闲坐姿,优雅的坐姿,优雅的站姿,技术坐姿,技术站姿。

视频背景:backgroundColor”: “transparent”, 透明或者白色。

视频格式:”videoFormat”: “webm”, 可以选择 MP4 和 webm 格式。如果视频背景选择了透明,这里就选择 webm 格式。

到这一步也就意味着配置全部结束了,然后执行这个代码框,就可以生成头像视频了。

代码框7
# download video to project folder. Note: An existing video file will be overwritten.
url = result.json()['outputs']['result']
local_filename = download_file(url, project_folder)
print(f'{local_filename} downloaded.')经过 6 分钟的等待之后,视频就制作好,程序会返回给我们的是一个下载链接。
使用之前的视频下载函数,即可将视频下载到本地。(视频无法展示)

现在结合这个视频,在看这个 SSML 格式,就能懂这些标签是做什么的了。(这个例子中讲法语的部分是没有生效的。)(视频无法展示)

<speak xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="http://www.w3.org/2001/mstts" xmlns:emo="http://www.w3.org/2009/10/emotionml" version="1.0" xml:lang="en-US"> <voice name="zh-CN-XiaochenNeural"> 这个例子展示了你可以用 SSML 让你的头像用不同的语言讲话,并且如何添加效果。 我们使用的是小辰的声音,它能用几种语言讲话。 <lang xml:lang="fr-FR">这里是多语言才华横溢的小辰用法语说话。我的声音很容易被识别。</lang> </voice> <voice name="zh-CN-XiaochenNeural"> 我可以用 15 种不同的风格讲话。 <s /> <mstts:express-as style="shouting">如果你想要一个喊叫的头像,对我来说没问题!</mstts:express-as> <s /> <mstts:express-as style="whispering">或者怎么样,来点耳语对话?</mstts:express-as> 你可以在我的语言中插入一个暂停 <break strength="medium" /> 使用一个断句标签。 使用音素来正确发音特定的单词,如 OpenAI 的 <phoneme alphabet="ipa" ph="ˈdɑli">DALLE</phoneme> 模型。没有音素,神经语音会错误地说 DALLE。 调整说话速度 <prosody rate="+30.00%">所以如果你想,我可以说得非常快</prosody><prosody rate="-40.00%"> 或者说得相当慢。</prosody> <prosody pitch="+10.00%">随意调整音调以提高声音。</prosody><prosody pitch="-20.00%"> 或者相反,如果你更喜欢那样。</prosody> <prosody volume="-80.00%">最后,这是你如何降低音量。</prosody> <prosody volume="+40.00%">或者让我说话更大声。</prosody> 我们希望这些示例能帮助你定制你的头像的沟通,以获得更引人入胜的体验。 <s /> <mstts:express-as style="friendly">玩得开心!</mstts:express-as> <s /> </voice> </speak>再看英文原版的,效果会更明显。
<speak xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="http://www.w3.org/2001/mstts" xmlns:emo="http://www.w3.org/2009/10/emotionml" version="1.0" xml:lang="en-US"> <voice name="en-US-JennyMultilingualNeural"> This example shows what you can do with SSML to let your avatar speak in various languages and how to add effects. We are using the voice Jenny Multilangual which is able to speak in several languages. <lang xml:lang="fr-FR">Voici le talent linguistique Jenny parlant français. Ma voix est bien reconnaissable.</lang </voice <voice name="en-US-JennyNeural"> I can speak in 15 different styles. <s / <mstts:express-as style="shouting">If you want a shouting Avatar, no problem for me!</mstts:express-as <s / <mstts:express-as style="whispering">Or what about some whispered dialog?</mstts:express-as You can insert a pause <break strength="medium" / in my speech with a break tag. Use a phoneme to pronounce specific words correctly like OpenAI's <phoneme alphabet="ipa" ph="ˈdɑli">DALLE</phoneme model. Without the phoneme, the neural voice would say DALLE, which is not correct. Adjust the speaking speed <prosody rate="+30.00%">so I can talk really fast if that's what you want</prosody<prosody rate="-40.00%"> or talk quite slowly.</prosody <prosody pitch="+10.00%">Feel free to adjust the pitch for more highness of the sound.</prosody<prosody pitch="-20.00%"> Or the opposite if you like that better.</prosody <prosody volume="-80.00%">Finally, here is how you reduce the volume.</prosody <prosody volume="+40.00%">Or make me speak louder.</prosody We hope that these examples help you to customize your avatar's communication for more engaging experiences. <s / <mstts:express-as style="friendly">Have fun!</mstts:express-as <s / </voice </speak
最后,意外的收获。玩了一天,就生成了 3 条视频,竟然倒欠微软爸爸 464 美刀,可是后面又显示无需付费。不得不感慨,数字人这玩意,成本是真的高!!!

最后的话
体验完微软数字人技术后,这也是用了这么多数字人平台后,第一次从底层用代码去制作出一个数字人。诚然,这次的尝试对于像我这样的普通用户来说,确实有些技术性和挑战性,从注册账号到操作界面,都让人觉得步步为营。
今天在实现的过程中,大家也看到了,遇到了各种各样的问题,但是有 GPT 的加持,也就迎刃而解了。正如爬山一般,虽然路途崎岖,却也充满了探索的乐趣和成就感。
微软的这项服务,虽然现阶段似乎更适合那些编程高手和技术达人,但相信,随着技术的发展和改进,未来一定会有更多适合我们这些普通用户的产品和服务出现。
期待有一天,我们都能轻松地打造和定制属于自己的数字头像,就像在科幻电影中那样激动人心。
想要获取整理了100+项目的教程合集吗?加我微信好友或者进入我的免费星球,即可免费领取!
![图片[2]-如何开始着手建群-副业项目库论坛-副业/创业-李又懂](https://geek.liyoudong.cn/wp-content/uploads/2023/12/%E5%9B%BE%E6%80%AA%E5%85%BD_4568ffb80a0cde51718167b4a3b66ed5_78552-1.jpg)
本文转自下方知识星球内《AI数字人》大航海,现在加入AI破局俱乐部,享受市面上价值数千的专业训练营(比如AI数字人、AI提示词、AI代写、AI视频等等),完全免费。想要踏入AI领域?快来扫码加入吧!
![图片[1]-如何开始着手建群-副业项目库论坛-副业/创业-李又懂](https://liyoudong-1305671160.cos.ap-beijing.myqcloud.com/2024/01/20240101120022299.png)
微信扫码加入后,可免费领取我的价值99/年的副业星球。(联系微信4314991邀请你加入)