一、AI 音频概况介绍
AI 音频是指由人工智能 (AI) 系统生成的计算机生成的声音。它是使用复杂的算法和深度学习技术来模仿人声的声音、音调和变化而创建的。这些 AI 生成的声音可用于各种应用程序,包括虚拟助手、聊天机器人、有声读物和导航系统。
AI 音频是通过在录制的人类语音的大型数据集上训练机器学习算法来创建的。这些算法学习识别数据中的模式,例如语调、语气和节奏,并利用这些知识生成听起来自然且像人类的新语音。
AI 音频最著名的例子之一是 Siri 的声音,Siri 是 Apple 设备上使用的虚拟助手。其他例子包括亚马逊的Alexa,Google Assistant和Microsoft的Cortana。这些人工智能声音已成为现代技术中越来越普遍的特征,预计未来将变得更加普遍。
一)AI 音频分类介绍
目前 AI 音频大概有以下6种分类:
- 音频处理与分析:使用AI来增强、编辑或转换音频信号。例如,噪声减少、回声消除或音频质量提升。
- 语音识别:将人类的语音转换为可读的文本。这是AI音频领域最广泛应用的技术之一,广泛用于助手技术、自动字幕生成和语音控制系统。
- 文本到语音(TTS):将文本转换为自然听起来的语音。这项技术使得机器能够以人类的声音读出文本,用于朗读器、虚拟助手等。这里是 openai 的 TTS 文件:https://platform.openai.com/docs/guides/text-to-speech 里面介绍了如何使用,感兴趣的同学可自行查看。
- 音乐生成:使用AI来创作音乐或生成音乐伴奏。AI可以分析音乐风格并创作出新的旋律和和声,有兴趣的同学,这一点可以去看元峰老师分享过的 AI 音乐相关帖子:t.zsxq.com
- 情感分析:分析语音中的情感倾向,用于客户服务、心理健康评估等领域。
- 声音合成:创建新的声音或模仿现有声音,例如合成名人的声音或创造全新的虚拟角色声音,也就是包括了声音克隆和声音创造,这部分也是此次手册重点介绍的部分 。
虽然现在的 AI 音频远没有 AI 绘图和 AI 文本技术成熟,不过已经可以使用在一些场景当中了。目前的 AI 音频可以说已经到了难辨真假的地步,我在破局线下会谈官的宣传视频开头就使用了 AI 音频复刻了洋哥的声音,因为没有让洋哥录制过,所以洋哥听了都直呼 “这咋听着是我的声音?”,大家可以听一下:https://t.zsxq.com/15hxyxgGb,所以这项技术还是很有的玩的。
二)AI 音频的发展路线
AI 音频的发展其实早在八十年代就已经开始,并逐渐融入到了我们的生活当中,我们平时使用的各种语音助手,甚至一些 MIDI 合成音乐也都是其产物,只不过现在随着 AI 浪潮的爆发,我们可以更加感受到这一技术的应用,也拉进了我们与 AI 音频的距离。AI 音频的发展路线简单来说分为以下几个阶段:
1. 初期探索(1980s-2000s)
- 基础语音识别:早期的语音识别系统主要依赖于基本的模式匹配和数字信号处理。
- 音频编辑工具:提供基本的音频处理功能,如音量调整、剪辑和合成。
- MIDI音乐合成:利用MIDI技术进行电子音乐的创作和播放。
2. 深度学习革命(2000s-2010s)
- 深度神经网络的应用:深度学习技术的引入大幅提升了语音识别和音频处理的性能。
- 高级文本到语音(TTS)系统:生成更自然和流畅的人声,如Google的WaveNet。
- 情感分析的应用:开始利用机器学习技术分析语音中的情感倾向。
3. 多元化与融合(2010s-2020s)
- 自然语言处理的整合:将NLP技术与音频处理结合,提升语音识别和理解的复杂度。
- 音乐生成和自动作曲:AI开始能够创作音乐,模仿不同风格和艺术家。
- 多模态交互技术:结合视觉、听觉和触觉信息,提供更丰富的用户体验。
4. 实时处理与边缘计算(2020s-)
- 边缘计算的集成:将AI音频处理能力集成到移动设备和物联网设备中,实现更快的响应和更低的延迟。
- 个性化和适应性:AI系统根据用户行为和偏好进行学习和适应,提供定制化音频体验。
- 实时语音翻译:利用AI进行即时的语音到语音翻译,打破语言障碍。
三)AI 音频使用风险提示
大家要注意的是,为降低使用风险和规避不必要的麻烦, AI 音频的制作和使用一定要遵循以下原则:
- 禁止使用 AI 音频对公众人物、政治人物或其他容易引起争议的人物进行声音的复刻及声音商用或其他不当用途。
- 使用 AI 音频制作的作品产出和传输的信息需符合中国法律、国际公约的规定、符合公序良俗。不将本整合包以及与之相关的服务用作非法用途以及非正当用途。
- 禁止将 AI 音频用于血腥、暴力、性相关、或侵犯他人合法权利的用途。
- 任何发布到视频平台的基于 AI 音频制作的作品,都最好要在简介明确中指明用于各种音频转换技术转换输入的源歌声、音频;若使用是自己的人声,或是使用其他声音合成引擎合成的声音作为输入源进行转换的,也最好在简介加以说明。
二、AI 音频应用软件
一)TTS 类 AI 音频软件
TTS 也就是 Text-to-speech,文字转语音可以说是视频创作者的福音了,前有剪映的小帅小美,后有 AI 音频爆发后的各种声音,通过消除对配音演员和录制会话的需求,大大减少了制作时间和成本。现在可以凭借 AI 音频多样化的可自定义语音和口音,使得创作者能够提高视频和语音内容的质量、创作更多引人入胜的内容,更好的吸引观众并将他们的视频提升到一个新的水平。 下面将给给大家介绍几款主流好用的 TTS 类音频软件:
- openai TTS
使用地址:https://platform.openai.com/docs/guides/text-to-speech
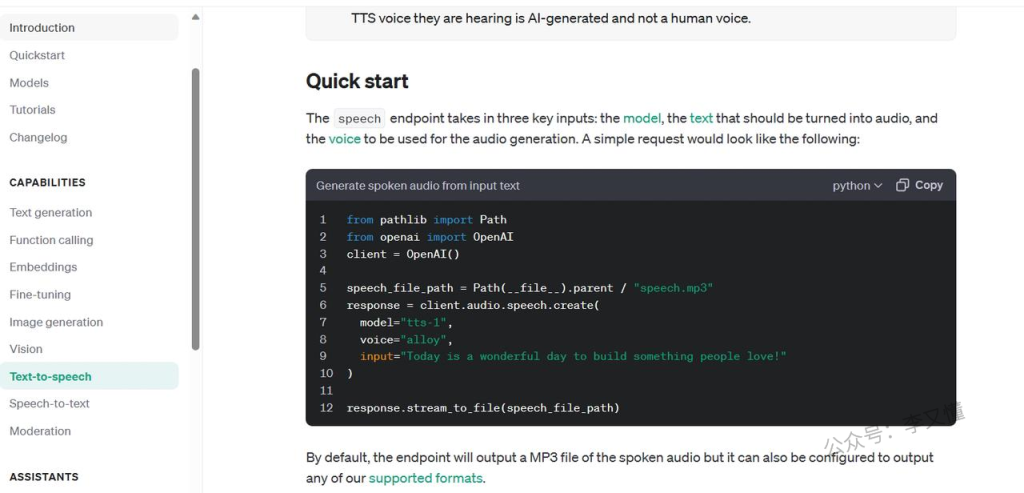
需要使用 openai 的音频 API,根据 API 提供 speech 基于 TTS(文本转语音)模型的终结点。它带有 6 种内置语音,可用于:
- Narrate a written blog post 叙述书面博客文章
- Produce spoken audio in multiple languages 生成多种语言的语音音频
- Give real time audio output using streaming 使用流式传输提供实时音频输出
优点是价格相比于 11 labs 便宜的多,openai 官方出品,音频效果质量肯定是有保证的,并且中文也较为自然,不至于是老外味儿的普通话。缺点首先是需要先获取 Open AI 的 API ,然后需要配置一堆文件,较为繁琐复杂,对小白和非程序员来说不太友好;其次,目前内置只有 6 个可直接使用的声音,若需要进行声音克隆就需要与 RVC 配合使用。
- TTS-Online
使用地址:https://www.ttson.cn/
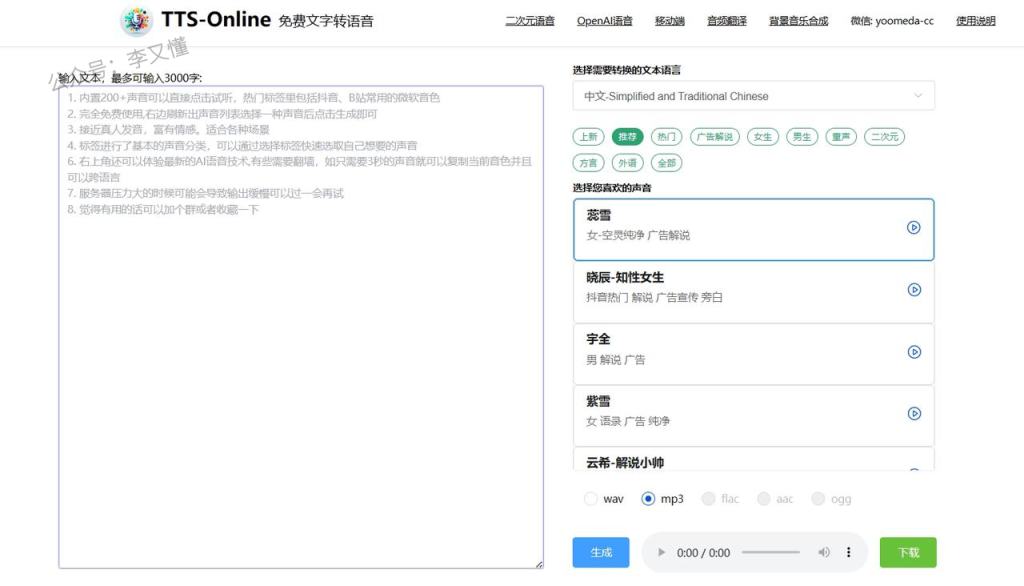
一款免费的语音转文字的线上应用,短小精悍,页面十分简洁,基本上属于上手就能用的软件,不需要配置各种代码,内置了已经训练好的几十种声音可供选择,包括不但不限于:中文及各国语言,甚至还有粤语等方言,甚至还有经典的渣渣辉的声音。用来直接做短视频的配音还是很有特色的。一大亮点在于内置了训练好的各种游戏或动画中二次元角色的声音,可以直接使用,做短视频或者有兴趣的同学可以打开思路进行创作。
- LOVO Genny
使用地址: https://lovo.ai/custom-voice
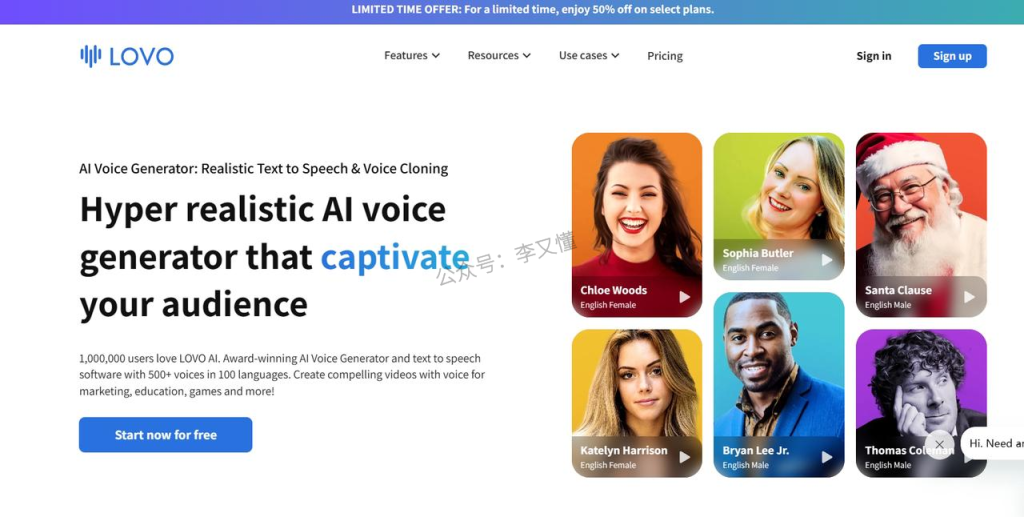
一款极其强大的AI语音生成器,可以做到逼真的文本到语音,拥有强大的语音克隆功能,以AI语音生成器为核心。具有超级丰富的功能集,可以提供无与伦比的画外音制作体验,包含100多种语言,声音不只是机器音,还会感受到输出语音情绪的爆发。甚至官网自称是世界上最先进的 AI 语音生成器哈哈哈,不知道 11labs 会不会同意。但是其功能确实强大,不仅内置了例如奥巴马,A 妹等名人的声音,更可以在线克隆自己的声音,或者其他任何你想克隆的声音,克隆完成后,输入文本即可在线生成。
这款软件让人惊讶的地方是可以节省文本输入时间,有些优点是不得不提一下:可以直接上传 word、pdf 等文档,直接读取文档中的内容填充到文本框中,不需要复制粘贴,但是文本内容要在5000字内,大家可以自行体验。
它的主要缺点就是要花钱啊,并且是要花大价钱啊,一开始会送基础版 20 分钟的免费额度,而订阅专业版需要 24 美刀一个月,比 ChatGPT plus 都要贵 4 美元,虽然好用,大家按需购买,或者换个思路:无限注册新邮箱,无限薅基础版 20 分钟的羊毛。
- llElevenLabs
使用地址:https://elevenlabs.io/
这款 AI 音频软件不仅支持 TTS,还支持 STS (speech to speech)和声音克隆。这款软件的优点首先是具有 STS 功能,也就是直接上传一段音频,可以将音频中的音色置换为这款软件的内置音色或者是你上传克隆的音色;其次,这款 AI 音频软件的中文语音生成质量也是较为优秀的,特别是上传一段高质量的中文语音数据集进行训练后,生成的效果是基本没有机器味儿或者老外味儿的。最后,它的额度是以字数计算的,免费版有 10000 字,订阅基础版后会有 30000 字,可以说是相当够用了。这款也是我经常使用的 AI 音频软件,方便省事儿,质量也说得过去。
它的主要缺点还是需要氪金,价格相比于 Genny 来说便宜很多,特别是首月还会打折,打折后基础版第一个月 1 美元,后续为 5 美元每月,并且有 6 种付费方案,最高是业务增长版 330 美元每月,所以还是让人肉疼的,并且只支持国外的支付方式,对于大多数人来说还是很不方便的。
二)SVC 类 AI 音频软件
SVC(Singing Voice Conversion),歌声转换,也就是类似变声器的东西,抽取一个人的声音作为训练数据,训练一个神经网络模型,学习他的声线;然后用模型在目标歌曲上做推理,即可实现用自己的声线唱目标歌曲。
- So-VITS-SVC
目前市面上主要使用 So-VITS-SVC 这款软件,这款软件的优点首先是可以训练任何自己想要的声音,其次是不仅可以转换普通的说话语音,还可以转换歌声,大家上半年在 B 看到的 AI 孙燕姿等各种 AI 歌手就是使用这款软件来做的。
而它的缺点就是需要本地部署,对电脑配置具有一定的要求,并且对声音数据集的要求较高,需要做好前期工作。不过大家不要有畏难情绪,这款软件的操作也是本手册重点介绍的的部分,本地部署、云端训练和数据集的处理都会进行讲解,具体操作请看下文。
三、AI 声音克隆
这一章节是本次航海语音克隆板块最重要的部分,请大家一定仔细学习,此章节将从两个方面展开,首先是了解声音克隆概述,其次是 AI 声音克隆实操。
一)AI 声音克隆概述
AI 声音克隆此次主要介绍两种,分别是 IVC 和PVC,IVC(Instant Voice Cloning )也就是即时语音克隆,允许用户近乎即时地从较短的样本中创建语音克隆;PVC(Professional Voice Cloning)也就是专业语音克隆,与 IVC 相比可以产出具有更理想效果的声音。
- IVC 即时语音克隆
即时语音克隆 (IVC) 允许使用者可以用约等于即时的声音作为样本,从较短的样本中创建语音克隆。创建即时语音克隆不会训练或创建自定义 AI 模型。相反,它依赖于训练数据中的先验知识来做出有根据的猜测,而不是对确切的声音进行训练。这对很多声音都非常有效。
这里的先验知识指的是系统在处理新的声音样本之前,已经从大量数据中学到的信息。这些信息可能包括不同人声的特征、语音模式、发音习惯等。系统利用这些已经学习的知识来识别和模仿新的声音,而不是从零开始学习每一个新声音的特性。这样做可以提高效率和准确性。
AI 将尝试模仿它在音频中听到的一切:包括说话人的速度以及语调、口音和音调、呼吸模式和强度,以及噪音、口部点击声等一切,包括可能混淆它的噪音和杂质,这就要求了你提供音频的纯净度要高。
IVC 基本上就可以满足我们日常的使用,性价比相对来说也很高,价格方面,IVC 的训练和在Elevenlabs 里只需要首月 1 美元即可,还是很超值的;时间方面,基本上只需要准备一个几分钟的纯净音频,等待几分钟就可以得到能直接使用的声音。
- PVC 专业语音克隆
专业声音克隆(PVC),与即时声音克隆(IVC)不同,后者允许你可以立即使用非常短的样本克隆声音,而 PVC 则允许你训练一个超逼真的声音模型。这是通过在大量的声音数据上训练一个专用模型来实现的,以产生一个与原始声音无法区分的模型。也就是说当你对 IVC 的结果不满时,或者你想一步到位生成一个难分真假的声音模型时,就可以使用 PVC。
根据前文所说,PVC的良好效果,依赖于大量的声音数据,并且声音数据的质量也要够高,这也就代表了得到最终的训练结果需要较长的时间,在 ElevenLabs 里训练的话差不多要一个月左右,并且要花至少 11 美元来订阅会员才可以定制,这里就推荐大家可以使用 SVC 自己训练,差不多一个下午或者一整晚就会得到满意的效果,具体时间和效果还是要视你训练所提供的数据集而定。
不论是 IVC 和 PVC 的应用和训练,都有以下几点需要注意:
- 如果你尝试克隆的声音超出了这些参数或超出了人工智能在训练期间所听到的内容,使用即时声音克隆完美复制声音可能会有困难。
- 录制音频的方式比样本的总长度(总运行时间)更重要。你使用的样本数量并不重要;重要的是总的组合长度(总运行时间)。大约1-2分钟的清晰音频,没有任何混响、杂质或任何类型的背景噪音,是最好的选择。也就是在录制的时候,最好没有其他杂音和混响,保证干净的人声。
- 其次关于声音的感情或者语调方面,AI 将尝试复制你提供的声音的表现。也就是说如果你以缓慢、单调的声音说话,没有太多情感,那么 AI 也会模仿这样的声音,当你富有感情的录制声音样本时,那么就会得到更具感情的 AI 声音克隆音频。但是!整个样本中的声音保持一致,不仅在音调上,而且在表现上也要如此。如果变化太大,把 AI 会搞懵掉,产出的效果自然会不好。
- 获得适当克隆的最重要方面是声音本身、语言和口音,以及录音的质量。音频长度比质量不太重要,但在某个点之前仍然扮演着重要角色。输入音频的最低长度应为1分钟。避免超过3分钟;这将带来很小的改进,并且在某些情况下甚至可能对克隆产生不利影响,使其更不稳定。
- 找到音量的良好平衡,使音频既不太安静也不太响亮。理想情况是在-23 dB至-18 dB RMS之间,真峰值为-3 dB。
- 声音克隆软件对比
下一部分就是 AI 声音克隆的实操部分了,大家可以根据教程的指导,完成自己的声音克隆制作,克隆后声音产出的作品可以与数字人进行联合使用,从而达到更好的视频效果。在实操之前,我们先来对比一下此次教学的两个软件的区别,此次主要教学两个方法分别是: llElevenLabs和 So-VITS-SVC 这两个克隆软件的使用。
选择这两款克隆软件的原因有三:首先,两款软件都是现在主流的声音克隆软件,上手虽较为简单,但是也不至于傻瓜式操作,需要教学指导;其次,两款软件的声音克隆效果都很优秀,且相对来说投入的金额和时间都较少,性价比优秀;最后,两款软件的使用门槛较低,绝大部分船员都可以直接上手使用。
为方便各位船员在不同使用场景下,选择最终的声音克隆方法,特别总结了两者的区别和优缺点,为方便各位船员查看,总结成下表,可以根据自己的需要对照表格中的各项信息来选择使用。
| llElevenLabs | So-VITS-SVC | |
|---|---|---|
| 电脑配置 | 网页操作,基本无配置门槛 | 本地运行要求:最低内存要求:8G(即需要64位操作系统)最低显存要求:6G;推荐使用英伟达NVIDIA系列显卡 |
| 氪金方面 | 最低需要 1 美元,若需 PVC 则最低需要 11 美元 | 本地运行:达到配置要求则0元云上训练:按训练时长计算,以 AutoDL 为例,1.88元/小时 |
| 网络环境 | 需要使用科学上网 | 不需要科学上网 |
| 上手难度 | 简单、快捷,对电脑小白友好 | 复杂,相对来说较难,对电脑小白来说门槛较高 |
| 训练效果 | 英文语音基本上无可挑剔;中文需看数据集质量和运气 | 只要你的训练数据够好,中英文效果都不错 |
二)AI 声音克隆实操
这一部分开始我们就要进行 AI 声音的克隆实操了,我将带领大家从训练数据集的准备到声音克隆效果的最终呈现逐步进行操作,最近电视剧《繁花》大火,大家对于胡歌的喜爱程度又是一阵直线上升,接下来我将以克隆演员胡歌的声音作为案例展开教程,对于最终胡歌声音的克隆结果仅作为教学使用,绝不用于任何商业用途,特此说明!
- 训练数据集准备
大家经过前文的解释可以看到,不论你是要用 IVC 还是 PVC 进行声音克隆,抑或是选择上述两款声音克隆软件中的一个,要想达到理想的训练效果都有一个干净且质量较高的训练数据集,数据集的时长根据你选择的训练方法而定,但是一定注意质量要优先于时长,如果你 30 分钟的一段训练音频充满了杂音,那还不如 10 分钟的干净纯人声效果好。
说到这里各位同学应该也知道了准备一个高质量数据集的重要性,在此,除了各位在准备声音样本也就是数据集时初步的筛选,例如人声清晰,富有感情,尽量无背景音,无杂音,保证声音中只有一个人声外,我将会提供两个工具来帮助大家提高你的声音数据集质量,分别是 UVR5 和 Audio Slicer,前者是去除伴奏和混响的工具,可以提升你音频的纯净度,后者是将音频进行切分,方便数据的训练。
为节省各位船员的时间,已准备好这两个工具的压缩包,下载后即可使用,由于 UVR5 文件过大,所以使用网盘进行分享,点击下面链接输入提取码后即可转存下载。
UVR5:
百度网盘链接:https://pan.baidu.com/s/1DJFCaT1KBccHXOZwkwfp7A 提取码:kpeo
夸克网盘链接:https://pan.quark.cn/s/4317146288f5
github网址(内含 Mac 版本):
https://github.com/Anjok07/ultimatevocalremovergui?tab=readme-ov-file
Audio Slicer:
百度网盘链接:https://pan.baidu.com/s/1M3KJrpmmDypTbUizr2iGMw 提取码:bfhc
夸克网盘链接:https://pan.quark.cn/s/eb751f49e8f8
github网址(内含 Mac 版本):
https://github.com/flutydeer/audio-slicer/blob/main/README.zh-CN.md
- 数据集准备工具使用方法
首先我们需要准备一段尽可能高质量的音频,也就是音频中只有一个人在说话,也尽量没有背景音和各种混响,这里我是准备了一段胡歌的演讲音频,这里注意音频格式要选择 WAV 格式。
- 准备好音频后,打开 UVR5 软件(软件的下载和使用方法也打包在了网盘中,可以阅读后进行下载安装)我们进一步提高音频的质量,将音频导入到 UVR5 中。这里要注意的是 UVR5 是非常占显存的,所以使用时最好单独只打开它一个软件,后台就不要开其他软件了,否则容易爆显存。
UVR5 打开后的界面和各功能区的介绍如下图所示:

- 这里我们点击 input 按钮将音频上传,并选择好处理完的音频文件输出目录

- 然后各项参数设置如下,点击 start 按钮等待完成,完成后会在你所选择的输出目录中出现一个文件后缀带有 vocals 的音频文件。

- 我们再将带有 vocals 的文件放进 input 栏中,这次是要将音频中的混响去掉,各项设置如图所示,设置完成后点击 start 等待完成即可,在输出目录中会出现一个文件名 xx_(Vocals)_(Vocals) 的文件,这样我们就得到了一段较为纯净的音频数据了。这里我们还可以将文件名改为全英文字母,例如我将我最终的音频文件命名为 HuGe(Vocals)_(Vocals),这是因为后续我们训练过程中要求使用全英文文件名,否则会报错。

- 接下来我们将这段最终的音频文件进行切分,不切分的话会导致训练时容易爆掉报错,切分也会增加训练成功的几率。这里切分就要使用 Audio Slicer 了,下载上面的压缩包后,在压缩包内找到如下文件,并双击打开。

打开后,界面如下:

- 接下来我们将处理好的音频拖入,并将各项参数修改如下,设置完成后点击 start 等待完成。这里要注意:输出目录路径一定要所有文件夹名称都是英文,不要出现中文或者空格之类的特殊符号,否则会报错!

我们可以去到输出目录里看一下切分后的文件大小,一般在 15 秒以下最好,如果切分后的音频还是很大,甚至到 30 秒左右了,那就再放到 Audio Slicer 里切分一下就好,这样训练时出的效果是最好的。到此,我们数据集的准备工作就结束了,接下来就可以开始声音的克隆了。
- llElevenLabs 声音克隆
这一部分我们将使用上面处理好的数据集在 llElevenLabs 中进行声音克隆,我们此次手册主要讲解 IVC 的使用方法,因为 PVC 的时间成本和经济成本过高,一般情况下是不建议大家去使用的,平时的使用场景使用 IVC 的声音克隆就能满足使用需求了。
- 打开网站:https://elevenlabs.io/,我们可以看到以下界面,没有账户的同学点击右上角的 sign in 按照引导进行注册即可,也可以直接选择图中标出的两个按钮中的一个进行登录,这里是可以使用谷歌账户进行登录的。

- 登陆完成后,界面如图所示,点击进入声音实验室

- 选择图中标注的 IVC 进行快速克隆,IVC 功能需要进行订阅才可以使用,点击订阅后直接选择 starter 这一档进行订阅即可,首月 1 美元,还是很值的。

- 选择我们准备好的数据集文件进行上传,这里需要注意的是,最多可以上传25个文件,上传完成后点击添加声音,静等魔法结束!上传界面如下:

- 等待结束后我们就可以得到我们想要的声音了,点击使用即可开始使用!

- 点击使用后会进入以下界面,这里如图标注出了各项功能区的功能,以及声音设定的各项设置,这里大家可以各种调整听一下效果,最后选择最满意的即可。例如我们选择 TTS 功能,输入如图内容,并点击下方的 generate 按钮即可,生成后它会自己播放,如果生产效果不满意可以再点击生成,如果满意可以直接点击下载。



- 见证奇迹的时刻,让我们来听一下“胡歌”对我们航线的鼓励!是不是特别真实!快去动手制作你感兴趣的声音克隆吧!
- So-VITS-SVC 声音克隆
由于这款软件对于电脑配置有一定的要求,一些小伙伴的电脑无法达到配置要求,而云上训练可以解决这一问题,让大家的使用门槛降低,可以更好的去操作学习,所以此次航海将教程内容设定为为云上使用 So-VITS-SVC 声音克隆。相比于上一款软件来说,这款软件的使用较为复杂,但是效果较好,相当于上一款软件的 PVC 功能,并且不仅仅是语音克隆实现声音的转换,还可以转换歌声。话不多说,我们正式开始~
- 打开算力云:https://www.autodl.com/,之前有账户的同学点击登录按钮,没有注册过的同学点击注册,这里可以使用手机号注册登录,或者选择微信登录,按个人需求选择即可。

- 充值账户:登录后界面的右上角会显示你的 ID,鼠标点击小三角以后选择充值,基本上充值 20-30 块左右就够用了。

- 充值之后选择算力市场,进入算力市场后,选择北京 C 区,如图所示,选择 V100-32G x型号,接下来就是租一台“新电脑”了。这里如果无卡可租时就多刷新几次页面,一般情况下都可以刷出来的。

- 选择镜像,社区镜像,在搜索框中搜索 so-vits-svc,找到图中所标示的版本,点击右下角创建即可。

- 等待创建,第一次创建大约要几分钟完成,创建完成后会自动开机,开机后点击 JupyterLab,出现以下界面后点击图中标红区域。其他部分不用管,可以看到这一区域中也写了一部分简介与教程,这是由 B 站大佬羽毛布团所创作的 so-vits-svc 项目中的一个分支 sovits4.1-stable,这一分支是由网友 kiss丿冷鸟鸟制作,相比于之前的几个版本更加的方便简明容易上手操作。

- 上传准备好的声音数据集,点击左侧 so-vits-svc 文件夹,依次按照图中所示的路径点击,并在 dataset_raw 文件夹中创建我们的声音数据集储存的文件夹,这里我们命名为 HuGe。之后打开这个新建文件夹,选择上方的上传按钮,从本地上传数据集,可以直接全部选择后点击打开,然后等待上传完成即可,上传完成后如图所示,即表示上传成功。



- 上传完成后,我们在右侧界面中找到如图所示的项目,点击选中后,再点击界面左上角的开始按钮,点击开始后右上角的圆圈变为实心,再变成空心圆后表示这一步运行完毕。

- 继续下一步项目文件夹命令,选中如图项目,点击运行,等待右上角变为空心圆。

- 选择 vec768l12 编码器,点击运行,等待运行完成。

- 选择 F0 预测器,选择第一个预测器,只删除第一个 “#” 后点击运行即可,不要删除后面的感叹号!等待右上角变为空心圆即完成运行。完成后是图二的样子,我这里是 78 条数据所以是 78/78 ,大家可以看自己的数据是多少来判断是否完成。


- 接下来我们按照如下路径修改参数,在左边的文件管理器中找到 autodl-tmp/so-vits-svc/configs,点击文件夹中的 configs.json,鼠标右键点击选择打开方式:editor,然后修改以下数值:“batch_size”: 6 改成12;”learning_rate”: 0.0001 改成 0.0002 ;”keep_ckpts”: 3 改成 10;修改完成后,用键盘 Ctrl+S 保存。保存完成后点击返回第一个界面。

- 开始训练,完成上一步设置好,要将左边的文件管理器保持在 so-vits-svc 这个文件夹下,然后找到如图项目,点击运行。点击运行后会卡几秒,大家耐心等待,只要右上角的圆圈还是实心的说明还在运行过程中。


- 等待训练,点击上一步运行后就是正在训练了,会出现如下图所示的界面,这里每训练 800 步时会保存一个模型,这里没有明确的训练完成时间,大家可以根据自动保存的模型和 loss 值去判断,loss 值一般在 28 左右是比较好的训练效果,我们可以找到距离这个数值近的保存模型使用。模型会保存在如下目录中:autodl-tmp/so-vits-svc/logs/44k,在这里你会看到 D 和 G 开头的文件,这些就是你训练保存的模型了。因为每 800 步保存一个模型,所以 D 和 G 后面的数值都是 800 的倍数。

- 接下来就是漫长的等待了,可能会长达几个小时甚至一整晚的时间。时间虽久,但是只需花一个租借算力的钱就可以获得 PVC 差不多的效果,还是很有性价比的,并且相比于 PVC 长达几天甚至排队一个月的训练时间,我们这点时间还是很快的。如果足够幸运的话,你保存的第一个 800 步附近的 loss 值是在 28 左右,那么你就可以进行下一步直接使用模型了,我这里是在 1600 步的时候获得了一个 27+ 的数值,那么我们就用这个模型进行下一步。

- 左侧文件管理器保持在 svc 这个目录下,点击右面界面上方的 “+” ,之后选择新建终端,然后将以下代码输入进去:python app.py,然后点击回车等待运行。运行完成后,会出现两个地址,复制第二个网址粘贴到一个新的浏览器窗口打开。


- 打开后上一步复制的网页后会出现如下界面,这样我们就可以使用我们训练的模型了。这里因为我要选择刚刚的 1600 步模型,所以如图所示模型选择是 G_1600.pth,而配置文件选择 config.json。只需要选择这两个选项,其他会自动配置,然后点击加载模型即可。

- 加载成功后显示结果如下

- 然后就可以正式使用我们训练的结果了!在这里可以将要转化声音的音频拖进去,也可以选择自己录音,上传完文件后点击下面图中的两个参数即可,然后点击音频转换,等待下面进度走完即可,大家耐心一下,一般要几十秒的时间,这里需要主要的是:因为转换音频是极其耗费显存和内存的事情,所以这里最多可以转换两分钟内的音频,否则会报错,也就是爆显存了。转换完成后点击下载即可。


- 见证奇迹的时刻,这里的原音频我选择了沪语版繁花中马伊琍的一段台词,现在我们来听听“胡歌”说起来是什么样子的!是不是很贴近胡歌的声音了!大家玩起来吧!
四、声音克隆应用案例
这一部分的应用案例都将以更加直观的视频方式进行效果展示,这些视频也让我们开拓了思路,这些视频中的声音都是由 AI 生成或者 AI 声音克隆生成。
一)广告
二)教育
三)自媒体(以短视频为例)
四)企业培训
五)播客
六)产品演示
以上就是本次数字人航线的声音克隆部分的全部内容,希望对大家有所启发,教程中出现疑问的地方欢迎大家在群里积极交流!
想要获取整理了100+项目的教程合集吗?加我微信好友或者进入我的免费星球,即可免费领取!
![图片[2]-如何开始着手建群-副业项目库论坛-副业/创业-李又懂](https://geek.liyoudong.cn/wp-content/uploads/2023/12/%E5%9B%BE%E6%80%AA%E5%85%BD_4568ffb80a0cde51718167b4a3b66ed5_78552-1.jpg)
本文转自下方知识星球内《AI数字人》大航海,现在加入AI破局俱乐部,享受市面上价值数千的专业训练营(比如AI数字人、AI提示词、AI代写、AI视频等等),完全免费。想要踏入AI领域?快来扫码加入吧!
![图片[1]-如何开始着手建群-副业项目库论坛-副业/创业-李又懂](https://liyoudong-1305671160.cos.ap-beijing.myqcloud.com/2024/01/20240101120022299.png)
微信扫码加入后,可免费领取我的价值99/年的副业星球。(联系微信4314991邀请你加入)